大脑如何区分「迪奥」与「奥迪」?Nature Communications最新研究揭秘
2022-12-03 神经科技 神经科技 发表于安徽省

大脑可对声音信号进行理解(解码),平均反应时间在50-300ms之间。在诸多特征中,声音大小、频率、元辅音、鼻音、擦音等声学信号激发的MEG信号更高,相比下,信息量大小及音节位置激发较小。
人脑是如何快速处理语音的?是不是跟计算机系统差不多?
最新一项研究显示,确实十分相近。
具体来说,当输入语音时,人脑会给每个单词打上一个时间戳,放进「缓存」中再进行处理,其上限为3个声音标记。
这项发现来自纽约大学研究团队,这两天刚登上「自然通讯」(Nature Communications)。

值得一提的是,科学家还发现不同语音在神经元听觉皮层会引发不同位置放电,加入位置信息编码。
因而,区分「迪奥」与「奥迪」,对我们来说十分容易。
具体他们如何得出这些结论?
往下看。
脑内有个「时间戳」处理语音信号
此前研究中,科学家更多着眼于大脑如何处理单个声音,对于「如何快速构建声音信息序列」尚存很多未知。
为此,他们找来21位受试者,母语为英语,听力正常且无神经系统疾病史。
这些受试者需要专心听2小时口语叙述,内容为4个短篇故事,语速为每分钟145-205个单词。
该过程中,每人大脑将接收50518个音素,13798个单词及1108个句子,脑磁图(MEG)将记录他们大脑内的神经反应。
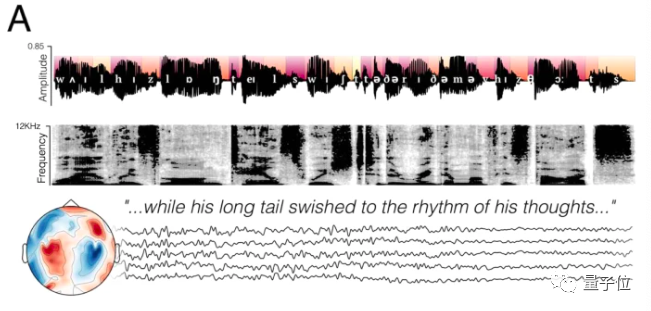
研究者首先观察了哪些声音特征影响了大脑编解码。
他们确定了31个语言特征进行观察,其中包括声音大小、音色、信息量、音节、语速、音节在单词句子里的位置……
结果显示,大脑可对声音信号进行理解(解码),平均反应时间在50-300ms之间。在诸多特征中,声音大小、频率、元辅音、鼻音、擦音等声学信号激发的MEG信号更高,相比下,信息量大小及音节位置激发较小。
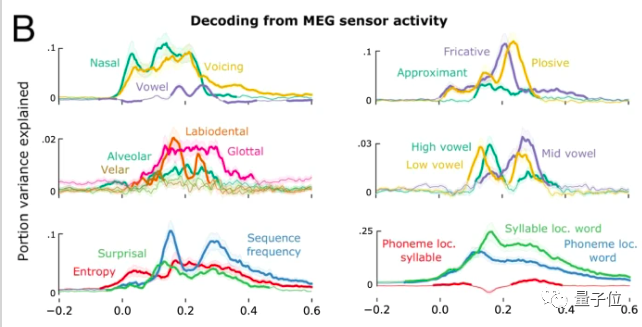
研究者进一步探究了多个音素输入的影响。
他们发现人脑对语音解码平均时间为300ms,这大于了实验设定的语音音素输入的78ms,这意味着大脑需要同时处理多个音素。
下图比较了连续音素输入下,听觉系统声音输入及神经系统反应的同步解码情况,能看出两者同步进行:

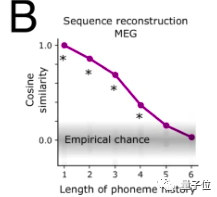
此外,人脑内对音素序列的有效缓存大于3个。
下图能看出,同时输入X个音素后,大脑对其还原能力的情况。3个语音标记内,基本能达到80%以上相似度,其运行原理与「时间戳」类似。
但大于等于4个,还原度就大幅降低:
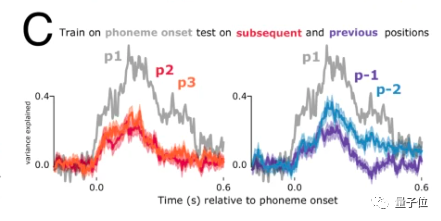
更进一步,研究者希望弄明白,大脑在同时处理多个语音过程中,如何不混淆它们?
他们先通过实验发现,同一个语音特征在脑内激活的位置是不变的,如下图P1音素,尽管存在位置不同,但激活的信号特征一致:
但由于音素顺序带有一套动态编码方案,研究者假定大脑将对输入音素进行延迟处理。
如下所示,通过观察不同特征输入在大脑内激活位置的变化,研究团队发现:
随时间推移,音量、爆破音、鼻音等声音特征信号仍集中在听觉皮层传递,但音素位置(最右)信号却传递到了额叶位置。
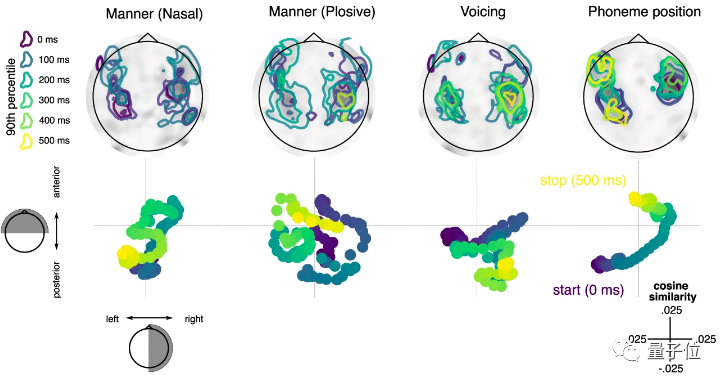
结合上述观察,研究者认为,虽然大脑存在「时间戳」可并行处理输入词语,同时,还通过一套位置的动态编码防止相邻语音被混淆。
此外,研究者还发现大脑能动态调整处理序列延迟和缓存记忆时长的多少,主要基于输入词语的信息量等特征,未来还需继续探索。
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言



