
统计模型选择的一些基本思想和方法
2018-10-31 高涛 MedSci原创

引言 有监督学习是日常使用最多的建模范式,它有许多更具体的名字,比如预测模型、回归模型、分类模型或者分类器。这些名字或来源统计,或来源于机器学习。关于统计学习与机器学习的区别已经有不少讨论,不少人认为机器学习侧重于目标预测,而统计学习侧重于机制理解和建模。个人更加直观的理解是,统计学习侧重于从概率分布来描述数据生成机制,除了预测之外,还关心结果(参数假设、误差分布假设)的检验,而机器学习侧重
引言 有监督学习是日常使用最多的建模范式,它有许多更具体的名字,比如预测模型、回归模型、分类模型或者分类器。这些名字或来源统计,或来源于机器学习。关于统计学习与机器学习的区别已经有不少讨论,不少人认为机器学习侧重于目标预测,而统计学习侧重于机制理解和建模。个人更加直观的理解是,统计学习侧重于从概率分布来描述数据生成机制,除了预测之外,还关心结果(参数假设、误差分布假设)的检验,而机器学习侧重于从函数拟合角度来描述数据生成机制,基本目的就是为了拟合和预测,缺乏严谨的参数、误差的检验机制,比如下式:Y=f(X)+ϵY=f(X)+ϵ 统计学习目标是获取Pr(Y|X)Pr(Y|X)X,Y,ϵX,Y,ϵ的分布假设,因此最后会衍生出对参数假设和误差分布的假设检验,以验证整个概率分布的假设的正确性,比如经典的线性模型、非参数回归等模型,预测能力并不是其主要目的; 而机器学习基本不会从概率分布的角度着手,虽然可能也会涉及X,YX,Yff,对误差的假设基本忽略,也不会涉及参数和误差的检验,模型好坏基本由预测效果来判断,同时也会提供一些比较一般的误差上界,所以机器学习中不会出现参数估计渐进性、一致性等结果
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言


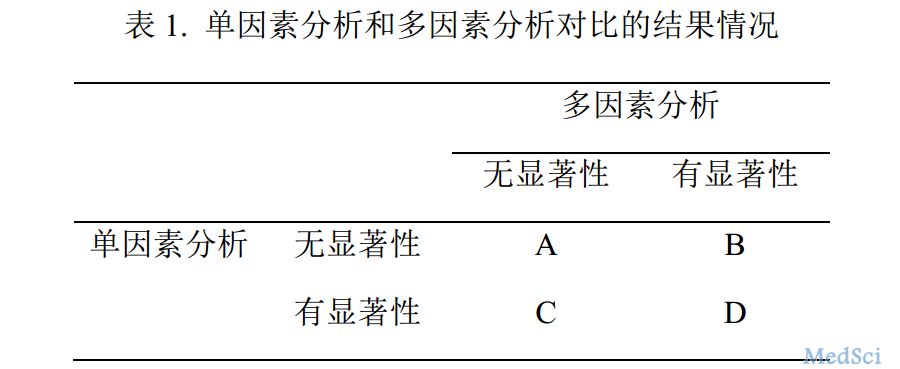

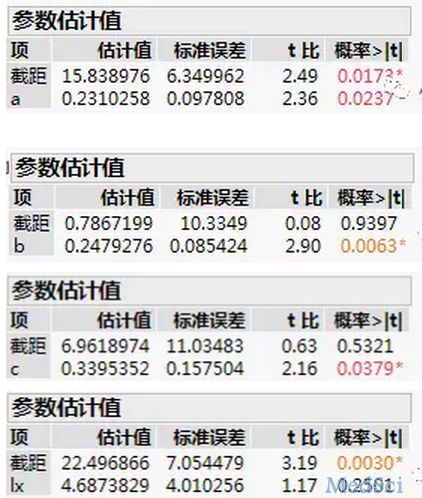

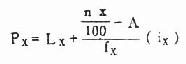



梅斯里提供了很多疾病的模型计算公式,赞一个!
88