
在大数据中找到新机遇的巢式病例-对照研究
2014-12-11 李楠,赵一鸣 北医三院临床流行病和循证医学中心

一、巢式病例-对照研究 病例对照研究是临床研究中较为常用的设计方案。如果将临床研究划分为“探索、培育、验证”3个阶段的话,病例对照研究是探索阶段的重要工具,通过病例对照研究,人们能够基于现成的资料,迅速的发现有价值的科学规律,进而开展进一步研究。但是正所谓鱼和熊掌不可兼得,病例对照研究通常从病例开始,再根据病例去寻找合理、可用的对照,并回顾性的收集数据;这一做法虽然效率高,但是往往会收到
一、巢式病例-对照研究
病例对照研究是临床研究中较为常用的设计方案。如果将临床研究划分为“探索、培育、验证”3个阶段的话,病例对照研究是探索阶段的重要工具,通过病例对照研究,人们能够基于现成的资料,迅速的发现有价值的科学规律,进而开展进一步研究。但是正所谓鱼和熊掌不可兼得,病例对照研究通常从病例开始,再根据病例去寻找合理、可用的对照,并回顾性的收集数据;这一做法虽然效率高,但是往往会收到各种偏倚的困扰。最常见的是回顾性收集资料带来的信息偏倚,以及对照与病例所属人群存在差异等等。
作为病例对照研究家族中的小兄弟之一,巢式病例对照(NCC,nested case control)研究产生20余年来,一直被使用得不温不火,这与其设计依附于大规模数据收集不无关系。所谓的巢式病例对照研究,与经典病例对照研究的根本区别在于病例和对照的产生方式(如图)。
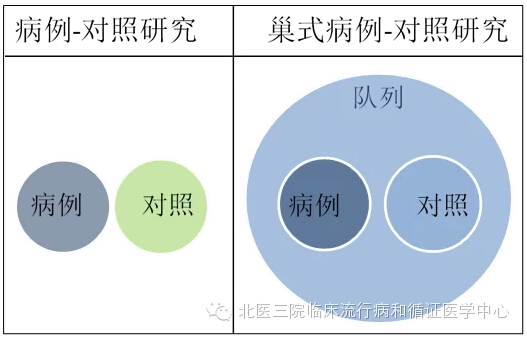
我们从图上不难看出,NCC最大的好处就是病例和对照的同质性较高;其次由于病例和对照均从已有的研究对象库中产生,所以有很多可供使用的准确的基线资料。
二、NCC的困境和机遇
NCC的思路看上去挺简单的,但是却难以大展拳脚,采用NCC设计的研究规模也仅能占传统病例对照设计研究的一个角落。最重要的原因之一,就是NCC需要基于现有的可供收集病例并选择对照的队列。在传统的临床研究构架下,临床工作和临床研究是割裂的。当临床医生希望发起一个研究时,需要从零开始,收集临床资料。同时,研究的资助也更多的来源于科研项目经费,研究周期短、产出需求急。在这样的研究土壤下,长出来的多数是短平快的“经济作物”。而NCC的设计,则需要一个生长周期较长的“松树林子”,在收货松木的同时,就能够顺手获得松子(NCC)。由此可见,在一段时间以来,国内有能力设计NCC的研究团队及其有限。
近年来,各大医疗结构都在加大临床数据信息化的力度,无论是临床资料还是生物样本,都在经历者收集、结构化、管理、存储、应用等诸多方面的变革。越来越多的信息技术企业也开始把注意力转移到了医疗大数据这块尚未完全成型的蛋糕上。预计5到10年内,在多数地区中心级别的医疗机构中,基于临床工作所采集到的数据将变得更为完整、结构化更强,届时所谓的“临床科研一体化”就将不仅仅是一个概念了。当然,目前已经有很多机构的优势科室走到了全国的前面。基于临床患者及其随访信息所产生的自然队列,尝试使用NCC的设计方案去探索新问题,这类研究的比例将逐渐上升。
其次,目前我国众多临床专科都在尝试建立覆盖全国的临床研究协同网络,基于网络开展本专科的大规模临床研究。从我们的视角看,协同网络的构建,更有价值的卖点就是形成了众多临床研究共同体。基于协同网络,更多的研究资料将被有计划、高质量的收集,自然也会产生无数个队列和病例注册研究。而作为医生个体,即便您来自于协同网络的末梢比如县级医院,只要您提出了有价值的研究思路,您也可能有机会参与到协同网络资料的分析中来。此时,作为效力优于病例对照研究的NCC,其发展前景同样非常值得憧憬。
三、好的NCC也不是自己长出来的
虽然在大数据的模式下,很多研究设计都可以套用NCC的概念。但是想完成一个高质量的NCC还是需要下一番功夫的。首要的问题,当然还是开发医生的脑力资源。换句话说,就是调动医生的积极性,让医生不仅仅是处理临床问题,而要注意到临床“问题”,把临床中的存在的困难和疑惑当成一个研究,返回头来从数据中探索答案。然后就是如何好好的设计一个研究了。
NCC的设计中,除了最常见的样本量等问题外,还有一个非常重要的问题,就是是否要通过“匹配”某些因素来选择对照。最简单的方法就是不匹配,仅在非“病例”人群中随机抽取对照,这样的问题在于,如果存在某些已知的具有很强效应的因素时,常常会掩盖掉一些效应不那么大,但是却没人发现过的规律。
除此之外,笔者个人认为,NCC中还存在着其他一些可以被匹配的因素,而这些因素往往在一般的病例对照研究中无法匹配,这就是“观察时间”。如果仅仅是随机抽取未发病的对象作为对照,那么很可能出现一种奇怪的现象:
我们有一个肿瘤术后患者的队列,队列从2004年起至今的10年间,逐渐形成了约500名某肿瘤患者构成的队列。在2014年底,我们注意到少数患者出现了一个新的未经报到的并发症,我们回溯以往的数据,发现该并发症在近几年的对象中都有散在发生。因此我们打算设计一个NCC来看看哪些因素可能与并发症的发生相关。
这时,由于队列中每个对象的入组时间不同,患者被观察到的时间也不尽相同。当我们用所有发生并发症的患者作为病例组时,如果随机的在没有发生并发症的患者中抽取对照,我们很可能会发现,对照组的平均观察时间与病例组不相等。这是为什么呢?首先,很多结局的发生,都与“时间”这一因素相关。很多并发症的发生也如此,随着观察时间的延长,患者发生某一事件的风险会逐渐增高。因此,当我们简单的抽取非病例作为对照时,就忽略了时间这一重要因素的效应。那么怎么破呢?最简单的方法就是,当知道某一结局的发生与时间相关时,我们按实际观察时间匹配的方式寻找每个病例对应的对照。即算出每个个体的实际观察时间(接受初始治疗至死亡或截止观察的时间),并按该指标进行匹配。这样就能有效的屏蔽时间的效应。
当然设计一个好的NCC并非一蹴而就的事情,如果您有机会参与到大数据下临床研究的竞争中来,不放多注意一下NCC这种方案的更多知识。
小提示:本篇资讯需要登录阅读,点击跳转登录
版权声明:
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言




#新机遇#
62
#对照#
50