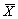
SAS第五课:定量资料的统计描述和t、u检验
2012-04-17 生物谷 生物谷

从本章开始,我们将正式开始使用SAS解决我们的统计问题。从前面的几章可知,SAS的主要功能是由不同的程序步来体现的。因此在以后的各章中,我们将对每种问题重点介绍一些常用的程序步,以及它们的输出结果的解释。 对于定量资料的统计描述和简单推断,SAS提供了三个强有力的程序步,它们是: UNIVARIATE过程 提供单个变量的详细描述和对其分布类型的检验。 MEANS过程 提供单个或多个变量
从本章开始,我们将正式开始使用SAS解决我们的统计问题。从前面的几章可知,SAS的主要功能是由不同的程序步来体现的。因此在以后的各章中,我们将对每种问题重点介绍一些常用的程序步,以及它们的输出结果的解释。
对于定量资料的统计描述和简单推断,SAS提供了三个强有力的程序步,它们是:
- UNIVARIATE 过程 提供单个变量的详细描述和对其分布类型的检验。
- MEANS 过程 提供单个或多个变量的简单描述,对于多个变量,它的输出格式紧凑,便于阅读。
- TTEST 过程 对变量进行t/u检验。
§
5.1 引 例例
5.1 文本文件“C:\USER\WTLI1_1.DAT”中已存入某市110名7岁男子童的身高资料(cm) ,请计算均数解:该题应首先用数据步建立一个数据集,然后调用
UNIVARIATE过程或MEANS过程来求出所需要的统计量。具体的程序如下:①
设定数据库环境:LIBNAME A 'C:\USER';
②
数据步,建立数据集:|
DATA A.WTLI1_1; |
|
INFILE 'C:\USER\WTLI1_1.DAT'; |
|
INPUT X @@; |
|
RUN; |
③
UNIVARIATE或MEANS过程,求出所需要的统计量:|
PROC UNIVARIATE DATA=A.WTLI1_1; |
PROC MEANS DATA=A.WTLI1_1 N MEAN STD CV ; |
|
VAR X; |
VAR X; |
|
RUN; |
RUN; |
例
5.2 某医生测得18例慢支炎患者与16例健康人的尿17酮类固醇排出量 (mg/dl)分别为X1和X2,问两者均数是否不同(医统第二版P19例2.17)?解:这是成组设计的两样本均数比较的
t检验,程序应首先建立数据集,然后调用TTEST过程进行检验,在检验的同时也可以得到两个样本的简单描述。①
设定数据库环境:LIBNAME A 'C:\USER';
②
数据步,建立数据集,这里采用直接输入数据的方法:|
DATA A.YTLI2_17; |
|
INPUT GROUP VALUE @@; |
|
CARDS; |
|
1 3.14 1 5.83 1 7.35 1 4.62 1 4.05 1 5.08 1 4.98 1 4.22 1 4.35 1 2.35 |
|
1 2.89 1 2.16 1 5.55 1 5.94 1 4.4 1 5.35 1 3.8 1 4.12 |
|
2 4.12 2 7.89 2 3.24 2 6.36 2 3.48 2 6.74 2 4.67 2 7.38 2 4.95 2 4.08 |
|
2 5.34 2 4.27 2 6.54 2 4.62 2 5.92 2 5.18 |
|
; |
|
RUN; |
③
TTEST过程,进行两样本的t检验。|
PROC TTEST DATA=A.YTLI2_17; |
|
VAR VALUE; |
|
CLASS GROUP; |
|
RUN; |
§
5.2 UNIVARIATE过程Univariate
过程对数值变量给出比较详细的变量分布的描述,其中包括:- 变量的极端值。
- 常用的百分位数,包括四分位数和中位数。
- 用几个散点图描绘变量的分布。
- 频数表。
- 确定数据为正态分布的检验。
5.2.1
语法格式Univariate
过程的语法格式如下:|
PROC UNIVARIATE [ DATA= <数据集名> [选项] ]; |
指定要分析的数据集名及选项 |
|
[ VAR <变量名列> ; |
指定要分析的变量名列 |
|
BY <变量名列> ; |
按变量名列分组统计,要求数据集已按该变量名列排序 |
|
FREQ <变量名> ; |
表明该变量为分析变量的频数 |
|
WEIGHT <变量名> ; |
表明分析变量在统计时要按该变量权重 |
|
ID <变量名> ; |
输出时加上该变量作为索引 |
|
OUTPUT OUT= <数据集名> |
指定统计量的输出数据集名 |
|
关键字= <新变量名列>... |
指定统计量对应的新变量名 |
|
pctlpts=<百分位数, ...> |
指定需要的百分位数 |
|
pctlpre=<新变量名列>] ; |
指定所需百分位数对应的输出变量名 |
如果省略所有非必需的语句和选项,则
UNIVARIATE过程按默认情况输出全部变量的全部常用统计量。5.2.2
语法说明【选项】
Univariate
过程常用的选项如下:- NOPRINT 禁止统计报告在OUTPUT视窗中输出
- PLOT 绘出茎叶图、箱式图和正态概率图
- FREQ 给出频数表
- NORMAL 对变量进行正态性检验
【关键字】
SAS
中用关键字来指定所需要的统计量,事实上结果输出中用的就是各种关键字,常用的关键字有:- 基本统计量
5.2.3
结果解释在默认的情况时,
Univariate过程会输出绝大部分统计量,此时的输出结果如下:Variable=变量名 变量标签
Moments 和矩有关的统计量 Quantiles(Def=5) 分位间距统计量
N 样本量 Sum Wgts 权重总和 100% Max 最大值 99% 99%百分位数 Mean 均数 Sum 总和 75% Q3 75%百分位数 95% 95%百分位数 Std Dev 标准差 Variance 方差 50% Med 50%百分位数 90% 90%百分位数 Skewness 偏度系数 Kurtosis 峰度系数 25% Q1 25%百分位数 10% 10%百分位数 USS 未校正平方和 CSS 校正平方和 0% Min 最小值 5% 5%百分位数 CV 变异系数 Std Mean 标准化均数 1% 1%百分位数 T:Mean=0 变量总体均数为0的t检验 Pr>|T| t检验的p值 Range 全距 Num ^= 0 变量值非0的例数 Num > 0 变量值大于0的例数 Q3-Q1 四分位间距 M(Sign) 变量总体均数为0的符号检验 Pr>=|M| 符号检验的p值 Mode 众数 Sgn Rank 变量总体均数为0的秩和检验 Pr>=|S| 秩和检验的p值
Extremes 极端值统计
Lowest Obs Highest Obs
老 幺 (观察值序号) 五大值(观察值序号)
次小值 (观察值序号) 四大值(观察值序号)
三小值 (观察值序号) 三大值(观察值序号)
四小值 (观察值序号) 次大值(观察值序号)
五小值 (观察值序号) 大哥大(观察值序号)
5.2.4
应用实例例
5.3 某地101例健康男子血清总胆固醇值测定结果已存入文本文件“c:\user\WT1_1.dat”中,请绘制直方图,计算均数解:
UNIVARIATE过程的默认输出中并不给出p2.5和p97.5,因此程序中要加以相应修改,最后在OUTPUT视窗中只会输出所需的几个统计量,具体程序如下:|
libname a 'c:\user'; |
指定c:\user文件夹为数据库a |
|
data a.wt1_1; |
数据步开始,指定要建立的数据集为a库的wt1_1 |
|
infile 'c:\user\wt1_1.dat'; |
采用外部文件读入方式,文件名为c:\user\WT1_1.dat |
|
input x @@; |
输入的变量为x,采用连续输入的格式 |
|
proc gchart data=a.wt1_1; |
调用绘图程序步gchart,所用数据集为a.wt1_1 |
|
vbar x ; |
绘出竖直条图,用于绘图的变量为x |
|
proc univariate data=a.wt1_1 noprint; |
调用程序步univariate,并且禁止在OUTPUT视窗中输出 |
|
var x; |
要分析的变量为x |
|
output out=temp |
指定输出数据集为work.temp, |
|
n=n mean=xbar std=s cv=cv median=m |
将n、mean、std、cv、median按指定变量名存入 |
|
pctlpts=2.5,97.5 pctlpre=per; |
指定输出p2.5和p97.5,其输出变量名以per开头。 |
|
proc print data=temp; |
将数据集work.temp的内容打印输出 |
|
run; |
开始运行以上程序 |
例
5.4 50例链球菌咽峡炎患者的潜伏期如下,计算其均数、中位数和几何均数(卫统p233 1.3题)。|
12~ |
24~ |
36~ |
48~ |
60~ |
72~ |
84~ |
96~ |
108~120 |
|
1 |
7 |
11 |
11 |
7 |
5 |
4 |
2 |
2 |
解:由于几何均数无法直接得到,因此将数据集加以对数变换,求出均数后再行反对数变换得到几何均数,程序如下:
|
libname a 'c:\user'; |
指定c:\user文件夹为数据库a |
|
data a.wt1_3; |
数据步开始,指定要建立的数据集为a库的wt1_3 |
|
input x f @@; |
输入的变量为x和f,采用连续输入的格式 |
|
x=x+6; |
将变量x的值更正到每个组段的组中值处 |
|
logx=log(x); |
定义新变量logx为变量x的自然对数,用于算出几何均数 |
|
cards; |
数据块开始 |
|
12 1 24 7 36 11 48 11 60 7 72 5 84 4 96 2 106 2 |
数据块 |
|
; |
数据块结束 |
|
proc print; |
将数据集a.wt1_3的内容打印输出 |
|
proc univariate data=a.wt1_3 noprint; |
调用程序步univariate,并且禁止在OUTPUT视窗中输出 |
|
var x logx; |
要分析的变量为x和logx |
|
freq f; |
指定变量f代表分析变量x的频数 |
|
output out=temp n=n mean=xbar logxmean median=m ; |
输出数据集和统计量的定义 |
|
data temp2; |
数据步开始,指定要建立的数据集为work.temp2 |
|
set temp; |
让work.temp2继承work.tmep的全部数据 |
|
g=exp(logxmean); |
产生新变量g,它等于elogxmean |
|
drop logxmean; |
在work.temp2中删除临时变量logxmean |
|
proc print data=temp2; |
输出数据集work.temp2中的数据 |
|
run; |
开始运行以上程序 |
![]()
§
5.3 MEANS过程Means
过程提供单个或多个变量的简单描述。和Univariate过程相比,它更倾向于描述已经明确样本所在总体符合正态分布的变量,因此它不提供百分位数,但可以提供95%可信区间。同时在多个变量输出时,它的输出格式紧凑,便于阅读。5.3.1
语法格式|
PROC MEANS [ DATA= <数据集名> [选项] |
指定要分析的数据集名及一些选项 |
|
[统计量关键字列表] ] ; |
列出需要的统计量 |
|
[VAR <变量名列>; |
要分析的变量名列 |
|
BY <变量名列>; |
按变量名列分组统计,要求数据集已按变量名列排序 |
|
CLASS <变量名列>; |
按变量名列分组统计,不要求数据集排序 |
|
FREQ <变量名>; |
表明该变量为分析变量的频数 |
|
WEIGHT <变量名>; |
表明分析变量在统计时要按该变量权重 |
|
ID <变量名列>; |
输出时加上该变量作为索引 |
|
OUTPUT |
指定统计量的输出数据集名 |
|
关键字= <新变量名列>... ] ; |
指定统计量对应的新变量名 |
5.3.2
语法说明【选项】
Means
过程常用的选项如下:- NOPRINT 禁止统计报告在OUTPUT视窗中输出
- MAXDEC=n 给出列表输出的最大小数位数,缺省值为2
【统计量关键字】
MEANS
过程中常用的统计量关键字有:- 基本统计量
![]()
5.3.3
结果解释和
Univariate过程不同,MEANS过程在默认情况下只输出样本量、均数、标准差、最小值和最大值,如例5.1的数据,如果MEANS过程不加任何选项,则输出如下:Analysis Variable : X 分析变量名为X
N Mean Std Dev Minimum Maximum
---------------------------------------------------------------
110 119.7272727 4.7413254 108.2000000 132.5000000
---------------------------------------------------------------
可见
Means过程的输出结构极为紧凑。5.3.4
应用实例例
5.5 给出例5.1的均数解:如果数据集
a.wt1_1已经建立,则程序如下:|
proc means data=a.wt1_1 n mean std cv lclm uclm t prt ; |
|
var x; |
|
run; |
§
5.4 TTEST过程顾名思义,
TTEST过程就是用于进行两样本均数的比较,它给出两总体方差齐和不齐时的检验结果,并同时做方差齐性检验。综合两者的结果,即可做出判断。![]()
5.4.1
语法格式|
PROC TTEST [ DATA= <数据集名> |
指定要分析的数据集名 |
|
[COCHRAN] ] ; |
要求在方差不齐时做COCHRAN近似 |
|
CLASS <变量名>; |
必需,指定一个两分类的分组变量 |
|
[ VAR <变量名列>; |
指定要检验的变量名列 |
|
BY <变量名列> ] ; |
按变量名列分组统计 |
5.4.2
结果解释以例
5.2的TTEST过程为例,它的输出结果如下:TTEST PROCEDURE
Variable: VALUE 分析变量名为VALUE
GROUP N Mean Std Dev Std Error Variances T DF Prob>|T|
样本量 均数 标准差 标准误 方差 统计量t值 自由度 p值
------------------------------------------------ ---------------------------------
1 18 4.45444444 1.32446314 0.31217896 Unequal -1.8132 31.2 0.0794
2 16 5.29875000 1.38200760 0.34550190 Equal -1.8179 32.0 0.0785
For H0: Variances are equal, F' = 1.09 DF = (15,17) Prob>F' = 0.8589
可见该结果分为三大部分:第一部分为两组各种描述统计量的值,第二部分分别给出两组所在总体方差齐和方差不齐时的
t检验结果,第三部分为方差齐性检验,因此该过程一共进行了三个假设检验。对于无效假设H0:两总体方差齐的检验结果为F' = 1.09,DF = (15,17),p = 0.8589,可见在本例中方差是齐的,从而应选用方差齐时的t检验结果,即t= -1.8179,ν=32,p=0.0785,按α=0.05水准,不拒绝H0,尚不能认为慢支炎患者与健康人的尿17酮类固醇排出量不同。5.4.3
应用实例例
5.6 某医院对9例慢性苯中毒患者用中草药一号抗苯一号治疗,得下列白细胞总数(109/L),问该药是否对白细胞总数有影响(卫统p225 2.3题)?|
病人号 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
治疗前 |
6.0 |
4.5 |
5.0 |
3.4 |
7.0 |
3.8 |
6.0 |
3.5 |
4.3 |
|
治疗后 |
4.2 |
5.4 |
6.3 |
3.8 |
4.4 |
4.0 |
5.9 |
8.0 |
5.0 |
解:该题为样本差值均数和总体均数为
0比较的t检验,TTEST过程无法完成。这里用MEANS过程来处理,程序如下:|
libname a 'c:\user'; | |
|
data a.wt2_3; | |
|
input x y @@; | |
|
tempvar=x-y; |
用新变量tempvar来记录同一病人治疗前后白细胞的差值 |
|
cards; | |
|
6.0 4.2 4.8 5.4 5.0 6.3 3.4 3.8 | |
|
3.4 3.8 7.0 4.4 3.8 4.0 6.0 5.9 | |
|
8.0 5.0 | |
|
; | |
|
proc means n mean std | |
|
stderr t prt ; |
利用Means过程检验差值总体均数是否为0 |
|
var tempvar; |
要分析的变量为tempvar |
|
run; |
开始运行程序 |
例
5.7 将钩体病人的血清分别用标准株和水生株做凝溶实验,测得稀释倍数如下。问两组的平均效价有无区别(卫统p226 2.5题)。标准株:
100 200 400 400 400 400 800 1600 1600 1600 3200水生株:
100 100 100 200 200 200 200 400 400解:程序如下:
|
libname a 'c:\user'; | |
|
data a.wt2_5; | |
|
input group x @@; | |
|
logx=log(x); |
将数据做自然对数转换 |
|
小提示:本篇资讯需要登录阅读,点击跳转登录
版权声明:
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。 在此留言 
评论区 (1)
#插入话题
相关资讯
SAS6.12教程说明SAS6.12教程:所用版本为SAS for Windows 6.12版,向下兼容至6.04版。大部分来自华西医科大学研究生用内部教材《SAS上机实习指导》(有删节)。 软件介绍>软件介绍 一、概况: SAS系统全称为Statistics Analysis System,最早由北卡罗来纳大学的两位生物统计学研究生编制,并于1976年成立了SAS软件研究所,正式推出了SAS软件。SAS 
SAS第三课:SAS程序基本语法入门从本质上讲,SAS是一种完善的第四代计算机语言。因此要真正掌握它,我们仍然要抛开其华丽的外表,从学习它的核心――SAS程序开始。 现在,让我们将SAS看成一个计算能力极强的统计学白痴(之所以这样说,是因为它计算能力虽然极强,却只能帮你计算而不能提出自己的实验设计方案或研究方向来),而你有一个非常小的关于数据分析的问题要请它帮忙。自然你要开口提出请求,无论措辞是委婉动听还是直截了 
SAS第二课:SAS/ASSIST视窗简介SAS是一个庞大的系统,它由许多模块组成,每个模块分别完成不同功能。由于SAS最初是为专业统计人员设计的(这一点和SPSS恰恰相反),因此使用上以编程为主,初学者掌握较为困难。现在,微机操作系统已经进入了WINDOWS时代,而WINDOWS软件的一个重要特点就是易学易用。要想在市场中继续领先,SAS必须推出能体现WINDOWS软件这一特色的新界面,SAS/ASSIST视窗就是这一努力的结果。虽然它 
SAS第四课:如何用SAS做统计图统计图是统计描述的重要工具,它可以直观的反映出事物间的数量关系。因此,许多统计软件均提供了强大的统计做图功能。SAS的许多程序步,如Univariate过程等,也附有相应的绘图功能,这些我们拟在相关章节中讲述。本章将向大家介绍两个专门用于绘图的程序步――GCHART过程和GPLOT过程。前者用于绘制各种常用的统计图,而后者则用于绘制散点图。 在早期的DOS版本中,SAS只提供低分辨率图形(即用键 
SAS**课:SAS界面及基本操作概述欢迎进入SAS世界!十几年来,SAS系统凭借其强大而完备的功能在统计软件界独占鳌头。如今,操作系统已进入了Windows时代,SAS的Windows版本也已日渐成熟。因此我们将以其Windows 6.12版本为主讲述SAS系统的使用。 在本章,我们将首先对SAS系统的界面及各部分的功能作简要介绍,随后以一个简单的SAS程序为例,讲述一些常用的操作,为以后深入学习SAS打下基础。 扫描二维码下载梅斯医学APP,参与讨论!

| |


#SAS#
78