大数据和医工交叉时代下对医学统计的思考
2020-03-16 小白学统计 小白学统计

世界上最遥远的距离,不是两个人在天涯海角,而是两个人(一个医生,一个工科)坐在桌子对面,谈了一个小时,却发现一句都听不懂对方在说什么。
世界上最遥远的距离,不是两个人在天涯海角,而是两个人(一个医生,一个工科)坐在桌子对面,谈了一个小时,却发现一句都听不懂对方在说什么。
这是一种真实情况,我曾经坐在两个人中间,试图给他们当翻译(虽然两个人说的都是中文),我需要让医生明白,什么是标签、什么是召回率、什么是特征工程,我也同时需要告诉工科技术人员,我们要实现的目的是什么、数据如何收集等各种问题。
医工交叉目前很火,目前医学很多成果都是医工交叉的产物,如语音识别、疾病面容识别等。我们自己也在不断探索如何跟工科更好的结合,这并不容易。真正的医工交叉,不是简单地“医院收集数据、工科建立模型”,这太肤浅,而且往往容易因为沟通不充分而产生歧义。然而让医生和工科整天在一起沟通交流(各自说着对方听不懂的术语,而且都以为自己说的是最浅显的话),既痛苦且耗不起时间。
如果说还有一种解决这种令人不安的局面的方法,那就是有个医学统计专业人员在二者之间翻译一下。医学统计学家在以前承担着各种临床试验设计、流行病学调查设计、数据清洗与管理、数据统计分析等各种责任,现在华丽的转身,变成了医学与工科沟通的桥梁。
在目前“大数据”充斥着各个领域的时代,仍有不少人认为统计学已经过时了,一味热衷于各种机器学习、深度学习。不少医学统计学研究生也在学习期间紧张地开始看各种机器学习的书籍(当然这是好事,但如果基础没打好,也可能会越看越糊涂)。然而,诺奖得主托马斯·萨金特和任正非却说,“人工智能就是统计学”(虽然这句话存在争议),这无疑给统计学专业人员吃了一个定心丸。
所谓“人工智能就是统计学”这句话,就算不能说百分百正确,但绝对是有道理的。其实各种机器学习中的术语,很多都是统计学中的变形,然而这很难统一。且不说统计学与机器学习领域的统一,单是统计学的同一名词在不同应用领域就存在不同叫法(如稳健vs鲁棒、甚至变量的类型都不统一,如医学中就没有定距变量这种说法)。
不少医学统计学专业的研究生,就对机器学习中所谓的“标签”、“特征工程”等各类术语茫然不知所措。同样,跟工科老师提“变量”、“指标”这些,他们有时也需要反应一会儿。尽管工科老师可以做出最复杂的模型,有时却难以理解像“关联”这种最简单的词在医学中的表达。因为工科生眼中看到的,往往只是数据本身,而医学的数据分析,却渗入了大量的设计思路。
机器学习往往简单粗暴,就是不断调优,最终接近目标。简单地说,你想要一根香肠,你把肉从机器这头塞进去,那一头就努力给你出来一根符合你需求的香肠,中间怎么做的,你不用管(事实上,你可能也管不了)。
统计学则并非如此,你想要一根香肠,需要自己精挑细选,准备好各种原料(肉、葱姜蒜、油盐酱醋等),然后一点一点尝试,最终在自己的不断努力下,终于做出一个符合自己口味的香肠。机器最多只是帮你做成香肠的样子,调馅什么的都是自己手工完成的。
如何利用统计学的技术做出一个符合需求的香肠,这个要求难度比较高。新手和老手做出的绝对不一样。因为新手往往可能缺乏经验,不知道如何选各种原料,如果做得效果不好,可能也不知道如何分析问题出在哪里。而资深统计学家则可以快速想到各种可能的问题并加以解决。
如果利用机器学习技术,你想让机器帮你调馅,你只负责把肉塞到机器里,这时候新手和老手可能差别并不大,因为大家都知道怎么把肉放进去,至于机器里面如何调馅(参数调优),你就放心地交给机器好了。然而一个很关键的问题是,如果你选的原料不好,这个机器再厉害,也不可能做出一个口感很好的香肠。机器可以帮你调馅,但绝不可能帮你选原料。这一点是绝对是资深统计学家值得夸耀之处,也是不可替代之处。
有的医学统计研究生(包括一些老师)很喜欢这些机器学习方法,却轻视传统的统计学方法。我一个朋友就曾收到一个审稿意见(文章目的是用logistic回归建立一个预测模型),建议他不要用logistic回归建模,改成所谓的“高级”统计方法。听起来很可笑,然而的确有一些人对这些所谓的“高级统计方法”着迷。
事实上,统计学和机器学习技术不是什么低级和高级的划分,如果真要说的话,统计学应该是机器学习之父(个人观点),虽然有的机器学习方法表面上看起来好像跟统计学没什么关系,但深入进去,其实是满满对统计学的敬意。不能因为二代变得似乎先进了,就忘了上一代的功劳。比如logistic回归和神经网络,能说神经网络比logistic回归高级?
相比机器学习技术而言,医学统计学的分析需要更多经验积累,同一份数据,有经验的统计学家可能会更容易发现数据背后的一些问题所在,可以更好地找出数据背后隐藏的真正规律。而新手有时则会错失这些规律,看不到一些提示或信息,有时可能会沉浸在一些似乎有意义的假阳性中沾沾自喜,有时则会为未能发现有意义的结果而苦恼。
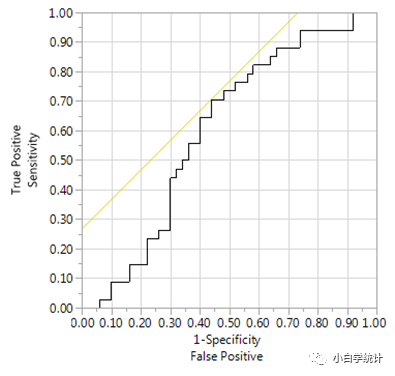
举一个例子,我要基于logistic回归建立一个预测模型(共有a、b、c三个连续变量)。我直接把因变量(二分类)和3个自变量扔到软件里建模,最后3个变量都没有统计学意义,模型的ROC曲线下面积只有0.6:
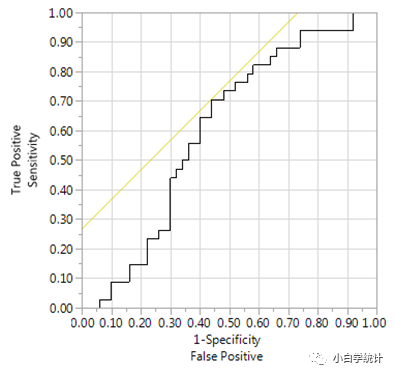
如果我用两层的神经网络,也把这3个变量扔进去,最后得到的ROC曲线下面积是0.86:

乍一看似乎让人印象很深刻,神经网络优于logistic回归。这也是前几年不少这类文章的结论(我个人就审过好几篇):通过对同一批数据,分别用logistic回归和神经网络(或其它机器学习方法)建模,最后一比较ROC曲线下面积,得出结论认为神经网络预测效果优于logistic回归。
这种结论是否正确,说实话,很难说。比如,你让一个老外(根本不知道什么叫水饺)来包水饺,然后同时也让一个机器自动包水饺,最后比较一下谁包的好吃,结果发现,机器包的好吃,然后宣扬:机器包的水饺优于人包的水饺。这个结论是否可靠呢?大家可以自己想想就明白。如果不是让一个老外包水饺,而是一个资深的厨师来包呢?最后还是说机器的更好吗?我想未必。
为什么神经网络的ROC曲线下面积高,因为神经网络在不断参数调优过程中,找到了一个最佳模型。比如本例就发现,两层的神经网络就优于单层神经网络,然而这是一个很复杂的模型,你甚至无法用公式、用语言去描述它。
为什么logistic回归的ROC曲线下面积低?问题不在于logistic回归模型本身,而是做分析的人。你如果没有经验,直接将数据扔到软件里,不考虑各种logistic回归所需的应用条件,自然得不到一个好的结果。
然而有经验的统计学家不会采用“直接把数据扔到软件里”这种方式。
如果仔细分析一下这3个连续自变量,其实根据经验很容易发现它们与结局并非线性关系,对一个本身就是个线性模型的logistic回归而言,你让它拟合一个非线性关系,当然效果不好(就像你用菜刀想一刀把西瓜写出个弧形,你永远做不到)。
事实上,当把数据重新分析,把3个自变量重新变换一下形式(可以是变量变换,也可以是根据实际情况将其划分为分类变量),我们就会发现,原来logistic回归拟合的效果一样很好,ROC曲线下面积为0.86:
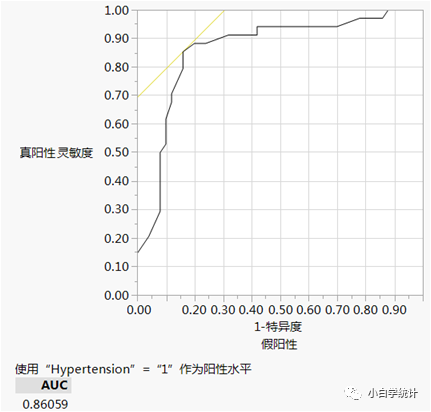
这个例子我只是想说,对于像logistic回归等这类似乎是“过时”的方法,需要更多的理解和深入分析。我的经验是:没有不好的方法,只有不会分析的人。就像摄影,真正懂得摄影的人,即使用手机也能拍出大片的效果。不懂的人,就算用单反拍的照片,始终总觉得差强人意。
当不同方法发生碰撞,很多医学统计学研究生就会困惑:我以前学的这些方法是不是过时了?我是不是应该转身去学习新的方法?方法是永不过时的,如果你觉得某种方法结果似乎不理想,我觉得首先应该自己想一下是不是自己没有用好,是不是有些问题你没有发现。《天龙八部》中乔峰用一套太祖长拳打败了少林寺的七十二绝技,是太祖长拳比七十二绝技厉害吗?非也!关键是看谁在用。或者像施瓦辛格在《终结者:创世纪》中说的:old, but not obsolete。旧的方法并不等同于无用的方法。
很多人把统计分析作为艺术来看待,如同作画、填词。确实如此。医学统计学的实用价值不是简单地理解几个概念、学会软件操作,计算某个结果。更重要的是,要学会理解分析思路,知道这些方法为什么要用、什么时候用、如何恰当地用,出现问题如何解决。
一个好的应用统计学家,不是说你会编程、会调参就够了,而是要从一开始收集数据就胸有成竹,从数据收集、清洗、整理,一直到如何分析,都要有明确的思路(就像一个好的厨师,从一开始选料过程就已经心里有数,他的能力绝不是只体现在最后一步炒菜上)。每一个变量都要清楚它为什么没有意义,是你的数据问题,还是你分析中漏掉了什么?我相信,一个真正的统计学家,是享受这一数据分析过程的。这种分析中发现问题、解决问题的过程,是一个让你不断提高的过程。
如果有的医学统计学研究生还在迷茫和彷徨,那其实没必要,在大数据和医工交叉时代下,医学统计学是变得更迫切和需要,而不是被取代。医学统计学家所考虑的角度,往往比工科更加实用,或者说,更贴近临床研究目的。
比如有一次讨论,一个工科老师先介绍一下他们跟医院合作做的一些结果,最后说,结果不算太理想,可能还需要进一步调参。我却从另一个角度提了一个建议:建议分不同年龄试试,因为这个疾病可能在不同年龄会有不同的变化和影响。这个建议看起来很简单,然而却并不是这么容易被想到。
从工科来讲,他们发现模型不够好,首先想到的可能就是继续调参,调到模型更好。临床大夫很难从这方面表达自己的想法,因为确实不懂工科他们在说什么。医学统计学家却会同时考虑模型和医学背景,提供更为中肯的、实用的建议。
所以,医学统计学家其实有很大的发挥余地,很多时候往往不经意的一些交流和碰撞,就会产生很多火花。我个人是深有体会的,与不同专业的人聊起来,往往会发现一些新的想法和问题。
最后给医学统计学研究生或新入行的人的建议就是:不要被当前各种层出不穷的新名词、新技术弄得眼花缭乱,也没有必要一味追求所谓的新方法和新技术(这些应该是一个自然而然的学习过程,而不是一个硬性拔高的过程),否则你会发现你好像永远跟不上技术的更新,永远处在焦虑之中。最好的方式就是:打好统计学基础,再去尝试接触自己需要的方法,你会发现很多方法其实都是触类旁通的,就像你学好了易筋经,你会发现再练其它招式都是事半功倍。
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言







#医学统计#
43