
利用SPSS Tables快速建立高质量的报表
2014-03-07 MedSci MedSci原创

经常需要将分析结果呈现给决策者、同事、客户或其他人,但是,制作报表是一个非常费时间、反复尝试的过程。SPSS Tables对于表格的结构具有“所见即所得”的特点,帮助你在较少时间里,做出美观、精确的表格。MedSci小编提示,还可以利用这个功能建立临床病历管理,近似CRF表的功能。虽然目前还没有epidata这样方便,但是更易于上手。 1、什么
经常需要将分析结果呈现给决策者、同事、客户或其他人,但是,制作报表是一个非常费时间、反复尝试的过程。SPSS Tables对于表格的结构具有“所见即所得”的特点,帮助你在较少时间里,做出美观、精确的表格。MedSci小编提示,还可以利用这个功能建立临床病历管理,近似CRF表的功能。虽然目前还没有epidata这样方便,但是更易于上手。
1、什么是SPSS Tables
SPSS Tables,是SPSS产
品线的一个附加模块,使你能针对不同的客户轻松定制不同风格的报表,对数据进行描述。该模块在创建表格的同时,能够实时更新,使您可以随时了解表格的外
观。例如,您可以设置描述性的和推论性的统计量,并定制表格的外观,以方便您的客户理解表格的信息。制表完成后,您可以将表格以Word,Excel,PowerPoint,以及HTML格式导出。在SPSS新版本均有此模块。
简单一句话:SPSS Tables相当于Excel中的数据透视表,但是比Excel的数据透视表要强大。
2、主要内容和特点
具有简单、独立和统一的特点
简单,拖拽形式的表格构造器使您在选择变量和选项的同时,预览表格外观
独立、统一的表格构建器,而不是以多菜单和对话框形式相应于不同类型表格,使报表工作更简单易行
主要内容:
—创建的表格以多达三维的方式展现:行、列、以及层
—所有维度的任意层次的嵌套变量
—在同一表格内显示多个变量的交叉列表
—在表格中并排显示多个变量的频数表
—显示表格中多个变量的所有类别,即使某个分类变量的某类别没有响应值
—行、列、层显示多个统计量
—在任意行、列、或层显示总计为某分类变量的部分子集创建小计
—设置分类变量类别的显示顺序,选择显示或隐藏某类别
—利用扩展的类别选项,更好控制数据的显示
根据表格中的任意摘要统计对类别排序
隐藏构成小计的类别-您可以隐藏表格中的类别而不影响小计
SPSS Tables可能的用途
SPSS Tables适用于以下情况:
调查研究:将复选题的答案与其他问题的回应浓缩到一个表格里
市场研究:处理缺失值并更改数据注释及格式
使用更多的统计量!
SPSS Tables提供了35种单元和摘要统计量。更方便地显示多重序列数据。
串接所有的维度,以在同一表格中显示包含不同统计量的各种变量。
更深入的分析
您可以在表格中加入更多的统计量,并对报告的内容拥有完全的控制能力。您可以从35种统计量中选择,计算您所需的摘要统计量,如最大值、最小值、均值、中值、众数等,以便对分析结果有更深层的认识。
SPSS Tables 能为您的表格加入比SPSS Base的交叉分析还要多的统计量,有效地展现分析结果。
您可以充分控制表格的结构,综合分析结果并将其以表格形式表达。这些方式包括复杂的行列表格(stub-and-banner tables)、列联表(contingency tables)及调查研究数据的列表。
您会发现以堆叠与巢状的方式,将大量数据压缩成有意义的报告表格是一件非常容易的事。同时,您能将变量放入所有维度(行、列、或层)中的任一层级中。
轻松地处理复选题与缺失值
复选题 - SPSS Tables清晰、精确地为复选题展示出答案。它能自动为复选题数据计算出百分比,您可决定计算出以回答人数或答案为基准的百分比。
缺失值 - 您将不会遗漏任何重要资料,因为SPSS Tables并不会将您的资料混在一起处理。不同的缺失值有不同的意义, SPSS Tables能将“不知道”、“不做答”、“不适用”或“拒绝回答”等“没有”答案区分开来。
控制表格内容并为其创造出一个优美的外观
SPSS Tables为您提供完整的表格控制权,让您能够自制表格,您可套用16个在TableLooks里预定义的表格格式,或自制表格格式。
SPSS Tables也能让您修改表格内容。您可以决定是否要包括行或列的统计量、哪些变量要综合起来及哪些统计量要计算。此外,可通过改变栏宽、加粗、画线或向左、向右或居中对齐,编制一个经过修饰的表格。您甚至能够直接指定标题及注解。
3、实例操作
下面的图示将告诉你如何操作
1)点击菜单“Analyze”—>“Tables”—>“Cusom Tables”

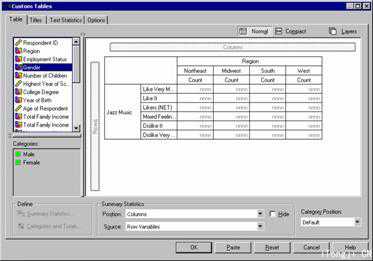
2)把要要分析的变量拖到表格构建窗口,如图所示,可以在把分类变量拖到分析窗口之前预览其类别(左下角)
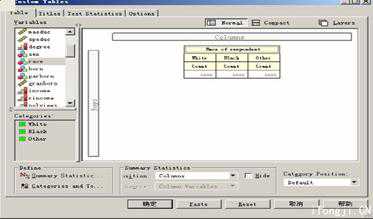
3)定义摘要统计量或类别和总计。有40多种统计量供您选择。
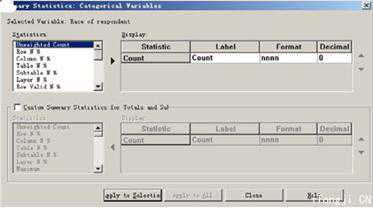
4)所有的结果都是以枢轴表格式输出的。可以应用TableLooks使输出结果更精美。同时,还可以将输出以Word、Excel、PowerPoint或者HTML格式导出。
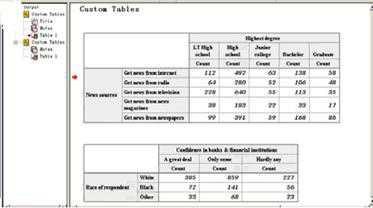
二、SPSS Tables应用的注意关键点
1、变量的类型:
注:想要变类型的话,直接用左键点变量,然后点右键(选择你想要的类型点左键)
2、output的数据形式设置,菜单操作见:(format是数据形式,Decimal是小数点的位数)
nnnn。简单数值。
nnnn%。在值末尾加上百分比符号。
自动。已定义变量显示格式,包括小数位数。
N=nnnn。在值前面显示 N=。在未显示摘要统计的表中,此格式可用于计数、有效 N 和总计 N。
(nnnn)。所有值都用括号括起。
(nnnn)(负值)。只有负值用括号括起。
(nnnn%)。所有值都用括号括起,并在值末尾加上一个百分比符号。
n,nnn.n。逗号格式。无论区域设置如何,均使用逗号作为分组分隔符,使用句点作为小数指示符。
n.nnn,n。点格式。无论区域设置如何,均使用句点作为分组分隔符,使用逗号作为小数指示符。
$n,nnn.n。美元格式。在值前面显示美元符号;无论区域设置如何,均使用逗号作为分组分隔符,使用句点作为小数指示符。
CCA、CCB、CCC、CCD、CCE。定制货币格式。在列表中显示每个定制货币的当前定义格式。在“选项”对话框(“编辑”菜单,“选项”)的“货币”选项卡中定义这些格式
3、常用的检验:
独立性检验(卡方验证)。此选项为表生成独立性卡方检验,该表的行和列中至少同时有一个分类变量。还可以指定检验的 alpha 水平,alpha 水平应该是一个大于 0 且小于 1 的值。
比较列的平均值(t-检验)。此选项为表生成列均值相等性成对检验,该表的列中至少有一个分类变量且行中至少有一个刻度变量。可以使用 Bonferroni 方法选择是否调整检验的 p 值。此外,还可以指定检验的 alpha 水平,alpha 水平应该是一个大于 0 且小于 1 的值。最后,虽然均值检验的方差始终只基于多重响应检验的比较类别;但对于序数分类变量,可只根据比较的类别或所有类别估计该变量。
比较列的比例(z-检验)。此选项为表生成列比例相等性成对检验,该表的行和列中至少同时有一个类别变量。可以使用 Bonferroni 方法选择是否调整检验的 p 值。还可以指定检验的 alpha 水平,alpha 水平应该是一个大于 0 且小于 1 的值。
4、常用的统计量:
均值。算术平均值;总和除以个案数。
中位数。一个值,大于该值和小于该值的个案数各占一半,第 50 个百分位。
众数。出现频率最高的值。如果存在出现频率相等的值,则显示最小值。
最小值。最小(最低)值。
最大值。最大(最高)值。
缺失。缺失值(用户和系统缺失值)计数。
百分位数。可以包含第 5 个、第 25 个、第 75 个、第 95 个和/或第 99 个百分位。
范围。最大值和最小值之差。
均值的标准误。取自同一分布的样本与样本之间的均值之差的测量。它可以用来粗略地将观察到的均值与假设值进行比较(即,如果差与标准误的比值小于 –2 或大于 +2,则可以断定两个值不同)。
标准差。对围绕均值的离差的测量。在正态分布中,68% 的个案在均值的一个标准差范围内,95% 的个案在均值的两个标准差范围内。例如,在正态分布(方差的平方根)中,如果平均年龄为 45,标准差为 10,则 95% 的个案将处于 25 到 65 之间。
和。值的总和。
合计百分比。基于总和的百分比。适用于行和列(在子表中)、所有行和列(跨子表)、层、子表和整个表。
总计 N。无缺失值、用户缺失值和系统缺失值的计数。不包含手动排除的类别(用户缺失类别除外)中的个案。
有效 N。无缺失值的计数。不包含手动排除的类别(用户缺失类别除外)中的个案。
方差。对围绕均值的离差的测量,值等于与均值的差的平方和除以个案数减一。度量方差的单位是变量本身的单位的平方(标准差的平方)。
有效 N 百分比。即使在表中包含用户缺失类别,也会从简单百分比基数中移去具有用户缺失值的个案。
计数。每个表单元格中的个案数或多重响应集的响应数。
未加权的计数。每个表单元格中的未加权的个案数。仅在加权有效时,此统计量才与计数有区别。
列百分比。每一列中的百分比。子表的每一列中的百分比(简单百分比)的总和为 100%。通常仅在具有分类行变量时,列百分比才有用。
行百分比。每一行中的百分比。子表的每一行中的百分比(简单百分比)的总和为 100%。通常仅在具有分类列变量时,行百分比才有用。
分层行和分层列百分比。嵌套表中所有子表的行或列百分比(简单百分比)的总和为 100%。如果表包含层,则每个层中所有嵌套子表的行或列百分比的总和为 100%。
层百分比。每个层中的百分比。对于简单百分比,当前可见层中的单元格百分比的总和为 100%。如果没有任何层变量,则此百分比等于表百分比。
表百分比。每个单元格中的百分比基于整个表。所有单元格百分比都基于相同的个案总数且总和为 100%(简单百分比)。
小提示:本篇资讯需要登录阅读,点击跳转登录
版权声明:
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言




真心不错
145