
多阶段整群随机抽样方法在流行病学研究中的运用
2014-05-05 付鹏钰 胡东生 顾东风 中国卫生统计

抽样调查是医学科研工作尤其是流行病学研究中常用的调查方法, 所抽取的样本对总体的代表性的好坏直接关系到结果的可信程度。基本的抽样方法如单纯随机抽样、系统抽样、分层抽样、整群抽样等各有优缺点112, 在大规模流行病学抽样调查中经常几种方法联合使用12, 32, 以使得抽样结果能够较好地代表实际总体的情况。笔者在学习过程中接触到亚洲心血管病国际合作研究( The Internation
抽样调查是医学科研工作尤其是流行病学研究中常用的调查方法,
所抽取的样本对总体的代表性的好坏直接关系到结果的可信程度。基本的抽样方法如单纯随机抽样、系统抽样、分层抽样、整群抽样等各有优缺点112,
在大规模流行病学抽样调查中经常几种方法联合使用12, 32,
以使得抽样结果能够较好地代表实际总体的情况。笔者在学习过程中接触到亚洲心血管病国际合作研究( The International
Collaborative Study of Cardiovascular Disease in ASIA, InterASIA
)中国部分(中国心血管健康多中心合作研究)这一复杂抽样调查资料, 该调查使用多阶段整群随机抽样(Multistage cluster sampling)方法, 选取对中国有代表性的样本。现介绍如下。
抽样过程
四阶段整群随机抽样将用于抽取具有代表性的样本。首先在中国分别从北部与南部地区各抽取5个省市,
所选出的省和地区应在地理位置和经济上具有各自的代表性。第二阶段的抽样为随机抽样,
从所选出的省中(包括北京、上海经济区)随机抽取1个县和1个城区, 总共抽取10个县和10个城区。第三阶段,
从每1个县和城区中随机抽取1个街道和1 个镇(村)(大约1000~ 2000户人家)。最后在所选取的街道和镇中随机抽取年龄在35~
74岁间的个体作为研究对象。
1. 第一阶段
抽样单位是省市。31个省和自治区大体以长江为分界线分为南北两组, 采用整群抽样方法从南部和北部分别抽取四个在经济和地理位置上具有代表性的省市。北京和上海经济区将被分别包括在北部和南部样本。
第一阶段抽取的结果, 北方省市包括: 北京经济区(北京市)、陕西省、山东省、青海省、吉林省; 南方省市包括: 上海经济区(江苏省)、湖北省、福建省、广西壮族自治区、四川省(见图1)。
2. 第二阶段
抽
样单位为县和城区。从第一阶段选取的各省中随机抽取1 个县和1个城区。对每一个所抽出的省(包括北京及上海经济区), 把所有县和城区分列出来,
并随机编号。随机号码最小的县或城区将被选入第三阶段。总共选出10个城区( 5个从北部, 5个从南部)和10个县( 5个北部, 5个南部)。
3. 第三阶段
抽样单位是街道、镇或乡(明确村)。对每一城区和县, 所有的街道和镇都被分列出来, 并随机编号。号码最小的街道或镇入选。总共10个街道(北部南部各5个)和10个县(北部南部各5个)将被选出。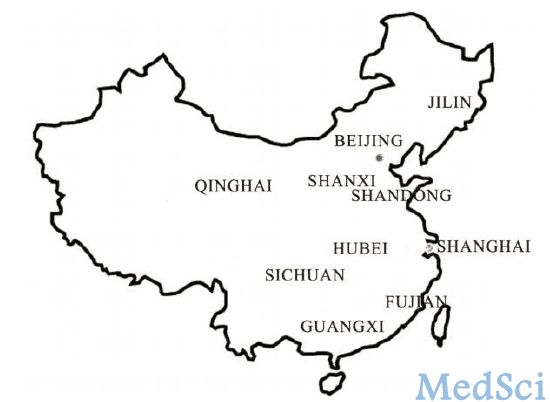
图1 InterASIA 研究的地区分布图
4. 第四阶段
抽
样单位是个体。全体街道或镇的居民名单将作为样本来源(限于年龄在35~
74岁间)。抽样过程将按男女分层以保证样本男女数均衡。每户只抽取一人作为研究对象以减少样本的相关性。抽样之前, 必须证实每个街道或镇有1 000
户以上的居民。如果没有, 需与临近的街道或镇(村)合并。预计80% 的应答率。这样, 每个现场每个年龄-
性别组需要至少60个个体以保证每一比较组有至少240人。
具体随机抽样步骤如下:
( 1) 将名单按男女性分成两层;
( 2) 每一个体一个随机号码;
( 3) 按随机号码排序;
( 4) 从最小的号码开始抽;
( 5) 将抽到的个体归类到各自的性别- 年龄组;
( 6) 重复上述过程直到男女性分别有400 人, 四个年龄组各自至少有60 人(每个点上共需要800人) ;
( 7) 核对每一家庭只抽取一个成员, 若有多个抽到, 留下第一位被抽到的;
( 8) 重复抽样过程直到800个人都来自不同的家庭。
调查对象和样本量
在
我国南方和北方(以长江为界) 分别根据人口地理状况、经济文化发展水平挑选有代表性的10个省市, 进行城市和农村分层,
然后运用多次分层整群随机抽样的方法, 在每个省市内分别随机抽样确定一个城市调查点(以街道居民委员会为单位)和一个农村调查点(以自然村为单位) ,
最后整群随机抽样各调查点年龄在35~
74岁居民800人(男女各400人)作为本次调查对象。总共在10省市的10个城市和10个农村点分别调查城乡居民共16 000人。
各城市街道和10个农村点分别调查城、乡男女性居民分别有400人, 四个年龄组各自至少有60人。按1990年我国人口构成比例得四个年龄组: 35~ 44, 45~ 54, 55~ 64和65~ 74岁, 分别应调查150, 100, 90,60人(表1)。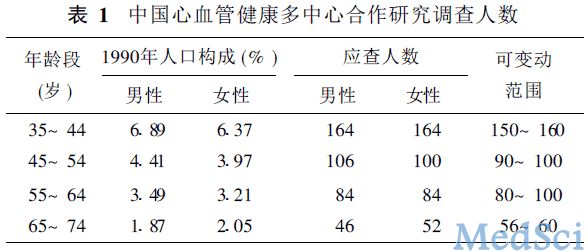
抽样结果
在
20个抽样单位中随机抽取19 012 人, 其中15 838人(男性7 684人, 女性8 154 人)完成了调查,总应答率为8313%
(男性8211%, 女性8415% ; 城市8212%, 农村8414% )。在完成调查的15 838人中, 共有15 540人年龄在35~
74岁之间。各年龄段人口构成与1990年我国人口构成相似(表2)。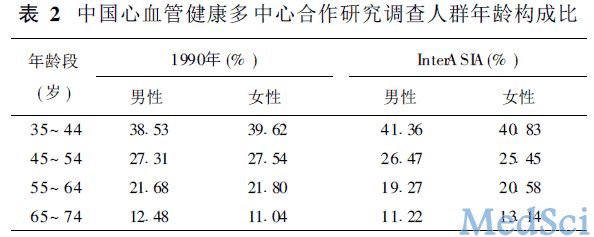
讨 论
在第一阶段的抽样过程中, 没有采用随机抽样是因为中国不同地区的经济状况及膳食差异很大, 随机抽样可能抽出不具代表性的样本。
InterASIA
调查中所采用的多阶段整群随机抽样方法综合运用了几种基本抽样方法, 它既利用了分层法抽样误差小, 整群法简单易行的优点,
又避免了整群法抽样误差大的缺点, 使各种方法相互补充, 扬长避短。InterAS IA 在全国范围内抽取15 838名年龄在35~
74岁之间的成年人, 先后进行南北、城乡分层, 再根据性别(男女各50% )和年龄分布(依据1990年全国人口调查资料) 分层,
这样的样本足以提供一个对我国心血管患病和危险因素水平的准确的估计。需要注意的是, 一般的数据统计分析方法是建立在单纯随机抽样的假设上,
但对于In terA SIA 这种在调查中采用了分层、整群等复杂抽样方法以获得更为精确的总体参数估计的大规模流行病学抽样调查数据,
必须通过加权的方式进行统计学校正, 否则将会导致错误的推断结论, 尤其是参数估计值的标准误及其可信区间可能会被严重低估。
{nextpage}
知识点:
多阶段抽样(Multistage sampling):
是指将抽样过程分阶段进行,每个阶段使用的抽样方法往往不同,即将各种抽样方法结合使用,其在大型流行病学调查中常用。其实施过程为,先从总体中抽取范围较大的单元,称为一级抽样单元,再从每个抽得的一级单元中抽取范围更小的二级单元,依此类推,最后抽取其中范围更小的单元作为调查单位。
多阶抽样与分层抽样和整群抽样的关系
多阶段抽样区别于分层抽样,也区别于整群抽样,其优点在于适用于抽样调查的面特别广,没有一个包括所有总体单位的抽样框,或总体范围太大,无法直接抽取样本等情况,可以相对节省调查费用。其主要缺点是抽样时较为麻烦,而且从样本对总体的估计比较复杂。
将总体分为若干个一阶单元,如果在每一个一阶单元中,都随机抽取部分二阶单元,由这些二阶单元中的总体基本单元组成的样本,在抽样的方式上,就相当于分层抽样;如果在全部的一阶单元中,只抽取了部分一阶单元,并对抽中的一阶单元中的所有的基本单元都做全面调查,这就是整群抽样。
因此,分层抽样实际是第一阶抽样比为100%时的一种特殊的两阶抽样;而整群抽样实际上是第二阶抽样比为100%时的一种特殊的两阶抽样,故也称单级整群抽样。令fi为抽样比,即有:
当时,二阶抽样可视为分层抽样,当时,二阶抽样可视为整层抽样。
多阶抽样与分层抽样的主要区别在于:
一、分层抽样是对总体中的每个一级样本群体进行全面入样,再对所有的样本进行抽查;而两阶抽样则把总体中所有的群体视为一阶单元,对这些一阶单元进行抽样,将抽出的样本再次进行抽样(两次都不是进行全面的调查),产生两级样本,最后综合估算出总的一级样本指标。
二、整群抽样是对总体中抽取的每个样本群体所包含的基本单元进行全面调查;而两阶抽样则把总体中所有的群体视为一阶单元,对每一个被抽中的一阶单元所包含的二级单元(即基本单位),不是进行全面的调查,而是再进行一次抽样调查(也称抽子样本)。即两阶抽样,产生两级样本,最后综合估算出总的一级样本指标。至于在综合估算的方式方法上,两阶抽样与整群抽样也是极其相似的,只不过前者为就被抽一级单元的样本指标进行综合估算,后者为就被抽样群体单元的全体指标进行综合估算。
多阶段抽样的特征
(一) 便于组织抽样。
当总体单元数目很大,分布很广时,若采用简单随机抽样,那么,编制全体总体单元的抽样框和现场实施随机抽样,都是相当困难的;如果采用等距抽样,则须将全部总体单元进行有序排列并等距抽取,也是很困难的;若采用分层抽样。则为提高抽样估计效率,需掌握全部总体单元的有关资料,按照分层的原则进行分层,然后到各层中去抽样,这一分层和大范围抽样的工作,是很繁重的;若采用单级整群抽样,也需掌握全部总体单元的有关资料,按分群的原则分群,并在抽中的群内作全面调查,这一分群和在群内做全面调查的工作也是很庞大的。
例如,我国有一亿八千万农户,为做农村住户调查,如果按上述几种方式进行抽样,其工作量之大是难以想象的。
若采用多阶段抽样,就可避免上述抽样技术中的麻烦。它可按现有的现有的行政区域或地理区域划分为各阶抽样单元,从而简化抽样框的编制便于样本单元的抽取使整个抽样调查的组织工作容易进行。多阶段抽样既保持了单级整群抽样的优点,又克服了他的缺点。
(二)抽样方式灵活,有利于提高抽样的估计效率。
多阶段抽样中,各阶段可以采用同一种抽样方法,也可以根据各阶单元的分布情况,采用不同的抽样方法。同时,还可以根据各阶单元分布情况的不同,安排不同的抽样比。
(三)多阶段抽样对基本调查单元的抽选不是一步到位的。
至少要经过两步抽样,这也是多阶段抽样与单阶抽样的区别所。
在。因此,多阶段抽样的随机性体现在每一阶单元的抽选上。而在各阶段可以充分利用辅助信息来增加效率。但由于在现实中,各阶单元大小相等的情形又几乎是不存在,所以对于各阶单元大小不等的多阶段抽样,如何保证每个基本单元都有相同的可能性被抽中,是一个较为复杂的问题,有待进一步探讨。
(四)多阶段抽样实质上是分层抽样与整群抽样的有机结合。
以两阶段抽样为例,从总体上所有一阶单元中抽取一部分单元,相当于从总体所有群中抽取部分群的整群抽样;而在每个抽中的一阶单元中分别抽取部分二阶单元,就相当于分层抽样。即先整群,后分层。因此,二阶抽样从技术上看是整群抽样与分层抽样的综合。
(五)多阶段抽样在抽样时并不需要二阶或更低阶单元的抽样框。
对于第一阶抽样,初级单元的抽样框是必要的。在以后的各阶抽样中,仅仅需对那些已抽中的单元准备下一级单元的抽样框。
(六)多阶段抽样还可用于“散料”的抽样,即散料抽样。
所谓“散料”,是指连续松散的、不易区分的个体或抽样单元的材料。例如一堆煤,一车水泥等。对于散料,抽样单元可以人为划分,也可以取其自然的单位。进行散料抽样时,一级单元是自然或人为划分的分装(例如一袋水泥),二级单元则是从分装中抽取一定数量(如一千克)的份样作调查。
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言




#流行病#
68