如此多的COVID-19预测模型,来看BMJ的系统评价!
2020-08-06 龚志忠 医咖会

截止到2020年7月27日,新型冠状病毒肺炎(COVID-19)疫情已波及全球215个国家和地区,报告累计确诊病例1637.4w例,死亡6.5w例,而实际上感染人数和死亡人数可能还要高的多。
截止到2020年7月27日,新型冠状病毒肺炎(COVID-19)疫情已波及全球215个国家和地区,报告累计确诊病例1637.4w例,死亡6.5w例,而实际上感染人数和死亡人数可能还要高的多。
疫情扩散导致对医院床位的需求大幅增加,医疗资源和设备出现严重短缺,为了减轻医疗系统的负担,同时也为患者提供尽可能更好的医疗服务,需要对COVID-19进行准确的诊断,并对疾病的预后情况进行有效的评估。
如果能够基于患者入院的基本特征,提前预测患者未来的预后是好还是差,就可以对患者进行分级,进而将有限的医疗资源进行合理的分配,这就需要用到我们在临床研究中经常用到的一个方法--预测模型。
针对COVID-19的预测模型,从基础的评分系统到高级的机器学习模型,各种各样的模型层出不穷。2020年7月1日,BMJ期刊发表了一篇系统综述《Prediction models for diagnosis and prognosis of covid-19:systematic review and critical appraisal》,对现有研究提出的COVID-19预测模型进行了系统评价和批判性评估。

研究人员通过计算机检索了2020年1月3日至5月5日在Pubmed、Embase、BioRxiv、medRxiv、arXiv等多个数据库中,公开发表的或同行审议的或预印本的研究论文,重点关注三种类型的预测模型:对COVID-19严重程度或疑似病例确诊为COVID-19进行预测的诊断模型,对COVID-19感染病程进行预测的预后模型,以及在一般人群中识别出COVID-19感染高危人群的预测模型。
研究人员使用基于CHAMS(预测模型研究系统综述的批判性评估和数据提取)核对表和PROBAST(预测模型偏倚风险评估工具)的标准化数据提取表来对预测模型进行评价,并按照PRISMA(系统综述和Meta分析优先报告条目)和TRIPOD(个体预后或诊断的多因素预测模型报告声明)报告规范对评价结果进行了报告。
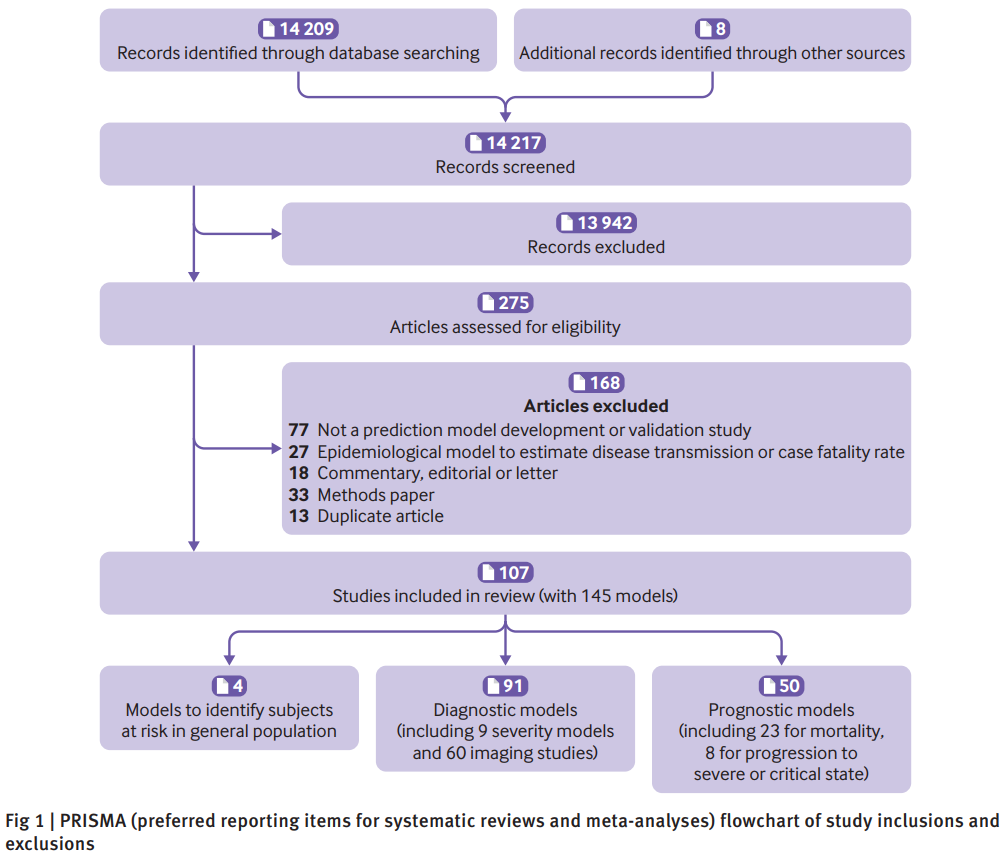
研究人员一共检索到了14209篇研究论文,并从其他途径获取了8篇论文,通过对题目进行筛选,剩余275篇进行摘要和全文筛选,最终有107篇论文145个预测模型符合纳入标准,见图1所示。
1、高危人群鉴别模型
对于一般人群发生COVID-19风险的预测模型共有4项,其中有3个模型均来自同一性研究,使用非结核性肺炎、流感、急性支气管炎或上呼吸道感染的住院患者作为替代结局,而没有使用任何COVID-19的病例数据信息。预测因素包括:年龄、性别、既往住院史、共患病以及健康的社会决定因素,C统计量分别为0.73、0.81和0.81。第4个模型是通过对戴口罩的人面部的热视频进行深度学习来确定是否有异常呼吸,但也与COVID-19无关。
2、诊断模型
对于COVID-19疑似病例中确诊为COVID-19的诊断模型共有22项,大多数模型是针对疑似COVID-19的患者。研究报告的C统计量范围在0.65-0.99之间。报告最多见的诊断预测因素有:流感样体征和症状(如寒颤、疲劳)、影像学特征(如CT肺炎体征)、年龄、体温、淋巴细胞计数和中性粒细胞计数。
对于COVID-19严重程度的预测模型共有9项,其中8项是成人模型,C统计量在0.80-0.99之间,另1项是针对儿童患者的研究。报告最多见的诊断预测因素有:共患病、肝酶、CRP、影像学特征和中性粒细胞计数。
有60项预测模型都提出基于影像学的图像结果可以支持COVID-19的诊断,或监测其病情进展过程。大多数研究都采用了胸部CT检查或X射线检查,还有一些研究使用了肺部超声等,C统计量在0.81-0.99之间。
3、预后模型
对于预测COVID-19确诊患者的预后模型共有50项,但是多数对于模型的使用(如什么时间使用、使用对象是谁)并没有明确的描述,预测范围从1天到30天不等,往往也没有具体说明。在这些模型中,有23项评估的是死亡风险,8项评估的是疾病进展到严重或危机状态的风险,剩下的模型评估的是其他结局事件的风险,例如康复、住院时间、入住ICU、气管插管、机械通气时间及急性呼吸窘迫综合征。
报告最多见的诊断预测因素有:共患病、年龄、性别、淋巴细胞计数、CRP、体温、肌酐和影像学特征。死亡预测模型的C统计量在0.68-0.98之间,疾病进展预测模型的C统计量在0.73-0.99之间,其他结局预测模型的C统计量在0.72-0.96之间。
4、偏倚风险
研究人员使用PROBAST工具对所有发表的研究偏倚风险进行了评估,结果显示所有的研究都存在很高的偏倚风险,这就意味着这些预测模型在实际的应用过程中,其预测能力可能要比研究中报告的低很多,因此有理由认为当这些预测模型应用到研究人群之外时,是非常不可靠的,没有一个可以推荐到临床中进行使用。
PROBAST工具共包括“研究对象”、“预测因子”、“临床结局”、“数据分析”四个领域共20项问题。在这107项研究中有53项研究在“研究对象”这一领域有很高的偏倚风险,这表明研究中的参与者可能不能代表模型的目标人群;有15项研究在“预测因子”领域存在较高的偏倚风险,表明预测因子在模型预期的使用时间内不可获得,没有明确的定义,或者受结局测量的影响;有19项研究,由于使用主观或替代结局(例如,非COVID-19导致的严重呼吸道感染),有理由担心结局测量所引起的偏差。
最令人担心的是,除1项研究外,其余研究在“数据分析”领域都存在非常高的偏倚风险,许多研究的样本量较少,这导致数据过度使用的风险增加,特别是在使用复杂建模策略的情况下。数据分析存在的问题涉及方方面面,例如没有报告模型的预测能力,没有报告模型的校准指标,或检查校准的方法不是最好的,外部验证的数据集可能不能代表目标人群等等。

预测模型的主要目的是支持医疗决策,因此,确定预测模型的目标人群显得至关重要,具有代表性的数据库才有可能被开发为预测模型并进行验证。同时,目标人群必须进行清晰的描述,从而可以来评估开发或验证模型的性能,以及在使用模型时能够清楚知道所应用的目标人群。但是不幸的是,目前的COVID-19预测模型研究往往缺乏对研究人群的充分描述,这使得使用者对模型的适用性产生了怀疑。
研究人员建议,模型开发者们都应该遵循TRIPOD报告规范来提高预测模型的质量。在开发新的预测模型时,建议在以前的文献和专家意见的基础上选择预测因素,而不是以纯数据驱动的方式选择预测因素。目前供过于求的不可靠的验证模型对临床实践没有任何用处,未来的研究应该更集中于验证、比较、改进和更新有前景的现有预测模型。
参考文献:
BMJ 2020;369:m1328(http://dx.doi.org/10.1136/bmj.m1328)
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言










#BMJ#
82
嗯,推荐
152
#预测模型#
85
#评价#
90
梅斯里提供了很多疾病的模型计算公式,赞一个!
91
这是篇好文,对新冠预测有价值
128