SparkR:数据科学家的新利器
2015-10-27 孙锐 程序员电

背景说明: SPARK作为大数据运算中最核心和常用框架之一,但有其自身特点,数据科学中最常用的语 言是R和python,在SPARK最新发布的1.4版中,加了一个新的模块SparkR,让SPARK框支持R语言,那么熟悉R语言人员可以直接操作SPARK。 SparkR是AMPLab发布的一个R开发包,为Apache Spark提供了轻量的前端。SparkR提供了Spark中弹性分
背景说明:

项目背景
R是非常流行的数据统计分析和制图的语言及环境,有一项调查显示,R语言在数据科学家中使用的程度仅次于SQL。但目前R语言的核心运行环境是单线程的,能处理的数据量受限于单机的内存容量,大数据时代的海量数据处理对R构成了挑战。
为了解决R的可伸缩性问题,R社区已经有一些方案,比如parallel和snow包,可以在计算机集群上并行运行R代码。但它们的缺陷在于没有解决数据分布式存储,数据仍然需要在主节点集中表示,分片后再传输给工作节点,不适用于大数据处理的场景。另外,数据处理模型过于简单,即数据分片在工作节点处理后,结果收集回主节点,缺少一个象MapReduce那样通用的分布式数据编程模型。
Hadoop是流行的大数据处理平台,它的HDFS分布式文件系统和之上的MapReduce编程模型比较好地解决了大数据分布式存储和处理的问题。RHadoop项目的出现使得用户具备了在R中使用Hadoop处理大数据的能力。
Apache顶级开源项目Spark是Hadoop之后备受关注的新一代分布式计算平台。和Hadoop相比,Spark提供了分布式数据集的抽象,编程模型更灵活和高效,能够充分利用内存来提升性能。为了方便数据科学家使用Spark进行数据挖掘,社区持续往Spark中加入吸引数据科学家的各种特性,例如0.7.0版本中加入的python API (PySpark);1.3版本中加入的DataFrame等。
R和Spark的强强结合应运而生。2013年9月SparkR作为一个独立项目启动于加州大学伯克利分校的大名鼎鼎的AMPLAB实验室,与Spark源出同门。2014年1月,SparkR项目在github上开源(https://github.com/amplab-extras/SparkR-pkg)。随后,来自工业界的Alteryx、Databricks、Intel等公司和来自学术界的普渡大学,以及其它开发者积极参与到开发中来,最终在2015年4月成功地合并进Spark代码库的主干分支,并在Spark 1.4版本中作为重要的新特性之一正式宣布。
当前特性
SparkR往Spark中增加了R语言API和运行时支持。Spark的 API由Spark Core的API以及各个内置的高层组件(Spark Streaming,Spark SQL,ML Pipelines和MLlib,Graphx)的API组成,目前SparkR只提供了Spark的两组API的R语言封装,即Spark Core的RDD API和Spark SQL的DataFrame API。
需要指出的是,在Spark 1.4版本中,SparkR的RDD API被隐藏起来没有开放,主要是出于两点考虑:
- RDD API虽然灵活,但比较底层,R用户可能更习惯于使用更高层的API;
- RDD API的实现上目前不够健壮,可能会影响用户体验,比如每个分区的数据必须能全部装入到内存中的限制,对包含复杂数据类型的RDD的处理可能会存在问题等。
目前社区正在讨论是否开放RDD API的部分子集,以及如何在RDD API的基础上构建一个更符合R用户习惯的高层API。
RDD API
用户使用SparkR RDD API在R中创建RDD,并在RDD上执行各种操作。
目前SparkR RDD实现了Scala RDD API中的大部分方法,可以满足大多数情况下的使用需求:
SparkR支持的创建RDD的方式有:
- 从R list或vector创建RDD(parallelize())
- 从文本文件创建RDD(textFile())
- 从object文件载入RDD(objectFile())
SparkR支持的RDD的操作有:
- 数据缓存,持久化控制:cache(),persist(),unpersist()
- 数据保存:saveAsTextFile(),saveAsObjectFile()
- 常用的数据转换操作,如map(),flatMap(),mapPartitions()等
- 数据分组、聚合操作,如partitionBy(),groupByKey(),reduceByKey()等
- RDD间join操作,如join(), fullOuterJoin(), leftOuterJoin()等
- 排序操作,如sortBy(), sortByKey(), top()等
- Zip操作,如zip(), zipWithIndex(), zipWithUniqueId()
- 重分区操作,如coalesce(), repartition()
- 其它杂项方法
和Scala RDD API相比,SparkR RDD API有一些适合R的特点:
- SparkR RDD中存储的元素是R的数据类型。
- SparkR RDD transformation操作应用的是R函数。
- RDD是一组分布式存储的元素,而R是用list来表示一组元素的有序集合,因此SparkR将RDD整体上视为一个分布式的list。Scala API 中RDD的每个分区的数据由iterator来表示和访问,而在SparkR RDD中,每个分区的数据用一个list来表示,应用到分区的转换操作,如mapPartitions(),接收到的分区数据是一个list而不是iterator。
- 为了符合R用户经常使用lapply()对一个list中的每一个元素应用某个指定的函数的习惯,SparkR在RDD类上提供了SparkR专有的transformation方法:lapply()、lapplyPartition()、lapplyPartitionsWithIndex(),分别对应于Scala API的map()、mapPartitions()、mapPartitionsWithIndex()。
DataFrame API
Spark 1.3版本引入了DataFrame API。相较于RDD API,DataFrame API更受社区的推崇,这是因为:
- DataFrame的执行过程由Catalyst优化器在内部进行智能的优化,比如过滤器下推,表达式直接生成字节码。
- 基于Spark SQL的外部数据源(external data sources) API访问(装载,保存)广泛的第三方数据源。
- 使用R或Python的DataFrame API能获得和Scala近乎相同的性能。而使用R或Python的RDD API的性能比起Scala RDD API来有较大的性能差距。
Spark的DataFrame API是从R的 Data Frame数据类型和Python的pandas库借鉴而来,因而对于R用户而言,SparkR的DataFrame API是很自然的。更重要的是,SparkR DataFrame API性能和Scala DataFrame API几乎相同,所以推荐尽量用SparkR DataFrame来编程。
目前SparkR的DataFrame API已经比较完善,支持的创建DataFrame的方式有:
- 从R原生data.frame和list创建
- 从SparkR RDD创建
- 从特定的数据源(JSON和Parquet格式的文件)创建
- 从通用的数据源创建
- 将指定位置的数据源保存为外部SQL表,并返回相应的DataFrame
- 从Spark SQL表创建
- 从一个SQL查询的结果创建
支持的主要的DataFrame操作有:
·数据缓存,持久化控制:cache(),persist(),unpersist()
- 数据保存:saveAsParquetFile(), saveDF() (将DataFrame的内容保存到一个数据源),saveAsTable() (将DataFrame的内容保存存为数据源的一张表)
- 集合运算:unionAll(),intersect(), except()
- Join操作:join(),支持inner、full outer、left/right outer和semi join。
- 数据过滤:filter(), where()
- 排序:sortDF(), orderBy()
- 列操作:增加列- withColumn(),列名更改- withColumnRenamed(),选择若干列 -select()、selectExpr()。为了更符合R用户的习惯,SparkR还支持用$、[]、[[]]操作符选择列,可以用$<列名> <- 的语法来增加、修改和删除列
- RDD map类操作:lapply()/map(),flatMap(),lapplyPartition()/mapPartitions(),foreach(),foreachPartition()
- 数据聚合:groupBy(),agg()
- 转换为RDD:toRDD(),toJSON()
- 转换为表:registerTempTable(),insertInto()
- 取部分数据:limit(),take(),first(),head()
编程示例
总体上看,SparkR程序和Spark程序结构很相似。
基于RDD API的示例
要基于RDD API编写SparkR程序,首先调用sparkR.init()函数来创建SparkContext。然后用SparkContext作为参数,调用parallelize()或者textFile()来创建RDD。有了RDD对象之后,就可以对它们进行各种transformation和action操作。下面的代码是用SparkR编写的Word Count示例:
基于DataFrame API的示例
基于DataFrame API的SparkR程序首先创建SparkContext,然后创建SQLContext,用SQLContext来创建DataFrame,再操作DataFrame里的数据。下面是用SparkR DataFrame API计算平均年龄的示例:
对于上面两个示例要注意的一点是SparkR RDD和DataFrame API的调用形式和Java/Scala API有些不同。假设rdd为一个RDD对象,在Java/Scala API中,调用rdd的map()方法的形式为:rdd.map(…),而在SparkR中,调用的形式为:map(rdd, …)。这是因为SparkR使用了R的S4对象系统来实现RDD和DataFrame类。
架构
SparkR主要由两部分组成:SparkR包和JVM后端。SparkR包是一个R扩展包,安装到R中之后,在R的运行时环境里提供了RDD和DataFrame API。
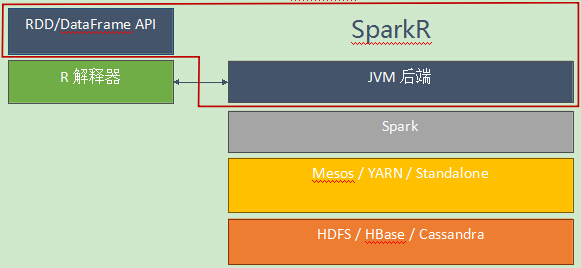
图1 SparkR软件栈
SparkR的整体架构如图2所示。

图2 SparkR架构
R JVM后端
SparkR API运行在R解释器中,而Spark Core运行在JVM中,因此必须有一种机制能让SparkR API调用Spark Core的服务。R JVM后端是Spark Core中的一个组件,提供了R解释器和JVM虚拟机之间的桥接功能,能够让R代码创建Java类的实例、调用Java对象的实例方法或者Java类的静态方法。JVM后端基于Netty实现,和R解释器之间用TCP socket连接,用自定义的简单高效的二进制协议通信。
R Worker
SparkR RDD API和Scala RDD API相比有两大不同:SparkR RDD是R对象的分布式数据集,SparkR RDD transformation操作应用的是R函数。SparkR RDD API的执行依赖于Spark Core但运行在JVM上的Spark Core既无法识别R对象的类型和格式,又不能执行R的函数,因此如何在Spark的分布式计算核心的基础上实现SparkR RDD API是SparkR架构设计的关键。
SparkR设计了Scala RRDD类,除了从数据源创建的SparkR RDD外,每个SparkR RDD对象概念上在JVM端有一个对应的RRDD对象。RRDD派生自RDD类,改写了RDD的compute()方法,在执行时会启动一个R worker进程,通过socket连接将父RDD的分区数据、序列化后的R函数以及其它信息传给R worker进程。R worker进程反序列化接收到的分区数据和R函数,将R函数应到到分区数据上,再把结果数据序列化成字节数组传回JVM端。
从这里可以看出,与Scala RDD API相比,SparkR RDD API的实现多了几项开销:启动R worker进程,将分区数据传给R worker和R worker将结果返回,分区数据的序列化和反序列化。这也是SparkR RDD API相比Scala RDD API有较大性能差距的原因。
DataFrame API的实现
由于SparkR DataFrame API不需要传入R语言的函数(UDF()方法和RDD相关方法除外),而且DataFrame中的数据全部是以JVM的数据类型存储,所以和SparkR RDD API的实现相比,SparkR DataFrame API的实现简单很多。R端的DataFrame对象就是对应的JVM端DataFrame对象的wrapper,一个DataFrame方法的实现基本上就是简单地调用JVM端DataFrame的相应方法。这种情况下,R Worker就不需要了。这是使用SparkR DataFrame API能获得和ScalaAPI近乎相同的性能的原因。
当然,DataFrame API还包含了一些RDD API,这些RDD API方法的实现是先将DataFrame转换成RDD,然后调用RDD 的相关方法。
展望
SparkR目前来说还不是非常成熟,一方面RDD API在对复杂的R数据类型的支持、稳定性和性能方面还有较大的提升空间,另一方面DataFrame API在功能完备性上还有一些缺失,比如对用R代码编写UDF的支持、序列化/反序列化对嵌套类型的支持,这些问题相信会在后续的开发中得到改善和解决。如何让DataFrame API对熟悉R原生Data Frame和流行的R package如dplyr的用户更友好是一个有意思的方向。此外,下一步的开发计划包含几个大的特性,比如普渡大学正在做的在SparkR中支持Spark Streaming,还有Databricks正在做的在SparkR中支持ML pipeline等。SparkR已经成为Spark的一部分,相信社区中会有越来越多的人关注并使用SparkR,也会有更多的开发者参与对SparkR的贡献,其功能和使用性将会越来越强。
总结
Spark将正式支持R API对熟悉R语言的数据科学家是一个福音,他们可以在R中无缝地使用RDD和Data Frame API,借助Spark内存计算、统一软件栈上支持多种计算模型的优势,高效地进行分布式数据计算和分析,解决大规模数据集带来的挑战。工欲善其事,必先利其器,SparkR必将成为数据科学家在大数据时代的又一门新利器。
孙锐,英特尔大数据团队工程师,HIVE和Shark项目贡献者,SparkR主力贡献者之一。
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言








#SpA#
50
#数据科学#
77
赞
142
好文
203