
这波「真实世界研究」热一定要赶上!学会这两个方法=研究成功了一半(纯干货)
2022-09-23 烤鸭小笼包 MedSci原创

近年来,真实世界研究掀起一波“热潮”,越来越多的科研人将目光投向了「真实世界临床研究」,各国也纷纷出台相关政策提供支持。
一、真实世界研究与混杂偏倚
评估一种治疗方法是否有效或者判断某个暴露因素是否与某疾病风险相关,最理想的试验就是在平行时空下,观察相同个体服药/未服药或暴露/非暴露后结局分别是什么。
很显然,这种试验设计是不现实的,但其实我们追求的这种理想化设计的核心就是希望干预组和对照组的人群特征尽可能同质化(Homogeneity)。因为如果失去了这个同质化前提,我们很难判断最后结局的差异究竟是源于暴露因素本身,还是源于这两组人群本身的差异。
例如,我们想探究吸烟与冠心病之间有没有相关性,如果招纳一批吸烟者、一批不吸烟者,不作任何校正或处理,直接比较他们患冠心病的比例,存在什么问题呢?
把情境具象化一点,一个不吸烟的14岁青少年没有冠心病,而一个65岁的老年男性烟民患有冠心病,我们说是因为吸烟导致的差异,你是否觉得这个推论不太科学呢?
没错,这里的年龄就是一个会干扰我们判断暴露与结局相关性的一个混杂因素(Confounder),因为我们知道年龄越大的人得冠心病的风险越高。同理,性别、生活作息、肥胖、其他合并症等等都有可能影响一个人患冠心病的风险。
随机对照试验(RCT)之所以一直以来被认为是评价临床证据的金标准,其宝贵就在于它的“随机(Randomization)”。
随机分组可以从概率学上最大化地消除组间差异,使两组人群在各变量的分布尽可能相似,实现我们追求的同质化假设。但是,RCT也有许多不足之处,例如成本高,特殊人群(如孕妇、儿童)中开展的伦理问题,苛刻的入组条件很难反映实际用药人群的特征,样本量较小,随访时间通常较短等。
真实世界研究(Real-world study)可以在上述这些方面补上RCT的短板,近年来无论在欧美还是国内,都在医药监管决策上发挥越来越重要的作用。
但真实世界研究的局限性也是显而易见的。因为其非干预性 (Non-experimental) 的特征,所有的治疗或暴露都发生在自然条件下,因此个体是否受到治疗或是否暴露于某因素,都不可避免地会受到其他因素的干扰,从而有很大可能引入混杂因素。
既然真实世界研究中的存在大量混杂因素,我们要如何校正混杂偏倚,来提高研究结果的可靠性和有效性呢?
二、校正混杂偏倚的方法
常见的几种校正混杂因素的方法包括限制(Restriction)、分层(Stratification)、随机化(Randomization)、匹配(Matching)、多元回归分析(Multivariable regression)等。
① 限制/分层:
这两种方法的逻辑是类似的,就是通过限制纳入排除标准或者把人群按照某一混杂因素分类再进行分析。
比如,如果我们担心年龄是一个混杂因素,那么在纳入患者时我们就仅纳入某一年龄段的患者,或者将患者按照年龄进行分层,再分别对各年龄段的患者进行分别比较分析,以减少组间差异性。
使用这种方法很显然我们能一次性识别或处理的混杂因素的数量非常有限,只适合混杂因素很明确且数量很少的情况。
② 随机化:
正如之前我们提到的RCT,可以使用随机化将组间差异平衡掉。这样的好处是无论是已知还是未知的混杂因素,均能通过随机化法最大化消除组间差异。但在真实世界研究中,几乎不可能进行随机化。
③ 多元回归分析:
在回归分析中纳入多个自变量,考察我们感兴趣的自变量在对其他自变量进行校正后,是否与因变量还有显著相关性。但纳入的自变量个数并不是没有上限的,一般认为对于 logistic 回归和 Cox 回归,结局事件应至少为 15-20 倍的自变量个数。
④ 匹配:
顾名思义,就是将两组中各方面特征都很相似的个体进行匹配,然后将匹配后的人群进行分析。那么如果他们的结局有差异,我们就可以认为这种差异是由治疗方案或暴露因素引起,而非源于其他因素。因此匹配可以起到类似“事后随机化”的作用。
今天,主要和大家介绍“如何用匹配法来进行真实世界研究的混杂偏倚校正”。其中,倾向性分析 (Propensity score analysis)是较常见的一种方法,也是下文介绍的重点。
三、倾向性评分及其应用
倾向性评分(Propensity score, PS)的定义是:个体在一组既定的协变量下,接受某种治疗/暴露的概率(The probability of participating in a treatment given observed characteristics)。
PS的优点是,可以将很多维的变量化归成一个一维的数字,在许多已有的观察性试验中,甚至纳入上百个协变量来计算PS。
PS可以用来将两组患者进行匹配,把相近PS的个体以1:1或1:n (一般n不超过4) 进行配对,也即倾向性评分匹配 (Propensity score matching, PSM)。
也可以利用PS对每个个体赋予一定的权重,相当于对样本进行了标准化,也即逆概率加权 (Inverse probability weighting, IPW)。
下面将逐一对PSM和IPW进行介绍。
① 倾向性评分匹配 (PSM)
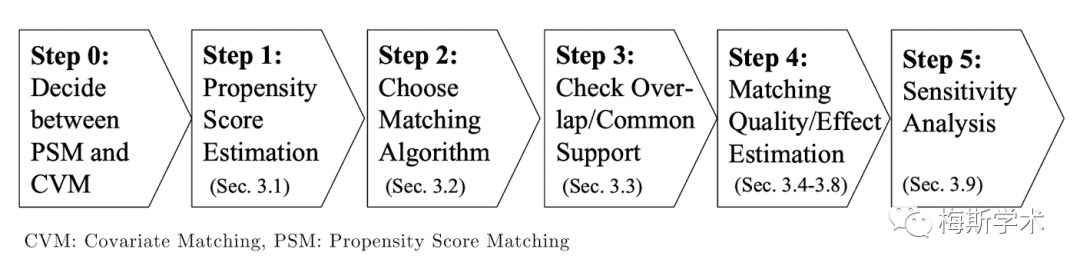
图2. PSM的步骤(Caliendo, 2008)
Step 1. PS的计算
这里我们讨论最常见的双臂研究,即研究对象只分成两个组别,Logistic回归一般是最常用的模型。
对于模型中自变量(即潜在的混杂因素)的选择,也有一定规律。某种因素成为混杂因素需要满足下列三个条件:
1) 在两组中的分布不同 (如A组平均年龄比B组大);
2) 会影响结局指标 (如年龄会影响得冠心病的风险);
3) 该因素不能处于治疗/暴露与结局的因果链上。

此外,自变量的选择也并非多多益善,过多的变量会引入高方差,影响匹配表现。
在确定了要使用的模型(logistic回归)和潜在混杂因素后,我们就可以以组别作为二变量的结局变量,选定的混杂因素作为自变量,开始跑模型。Logistic回归得到一系列协变量系数,而通过这些系数,我们可以计算出每个人被分配到A组或B组的概率,即PS。
Step 2. 匹配方法
当我们得到每个人的PS后,要如何将他们进行匹配呢?这时就需要制定一套匹配标准,目前有以下几种常见的匹配方法:
1) 最近邻匹配(Nearest Neighbor Matching):
顾名思义,在对照组中选择PS值最接近的个体与研究组中的某个个体进行匹配。
这里又要分两种情况,可替换 (with replacement) 和不可替换 (without replacement)。可替换表示对照组中的个体可以被选择匹配多次,而不可替换则表示对照组中的个体不能被重复取用匹配。
2) 卡钳匹配/半径匹配(Caliper/Radius Matching):
上述的最邻近匹配法会带来一个问题,对于某个体,如果即使他的最邻近匹配值也和其本身的PS值相差很大怎么办呢?
这时我们就要设定一个匹配容差 (match tolerance),也即卡钳值(caliper),希望要匹配的PS差值在此范围内。研究表明卡钳值取0.2倍的PS的标准差时可以消除原始估计中至少98%的偏差 (Austin, 2011)。
我们既可以选择卡钳值内的最近邻PS值作为匹配对象,也可以将卡钳值半径内所有PS值都纳入作为匹配对象,以期最大化地利用数据,这种方法又叫半径匹配 (radius matching)。
3)分层匹配(Stratification Matching):
将PS值的范围分层,再在每一层级中进行分析。有研究表明,一般5个层级可以消除掉大部分由混杂因素带来的偏倚 (Cochran, 1968)。
除此之外,还有一些比较高阶的匹配方法比如非参数匹配,包括核匹配和局部线性匹配 (Kernel and Local Linear Matching),这里不作过多介绍。上述介绍的匹配方法各有优劣,主要是偏倚和方差二者之间的权衡。
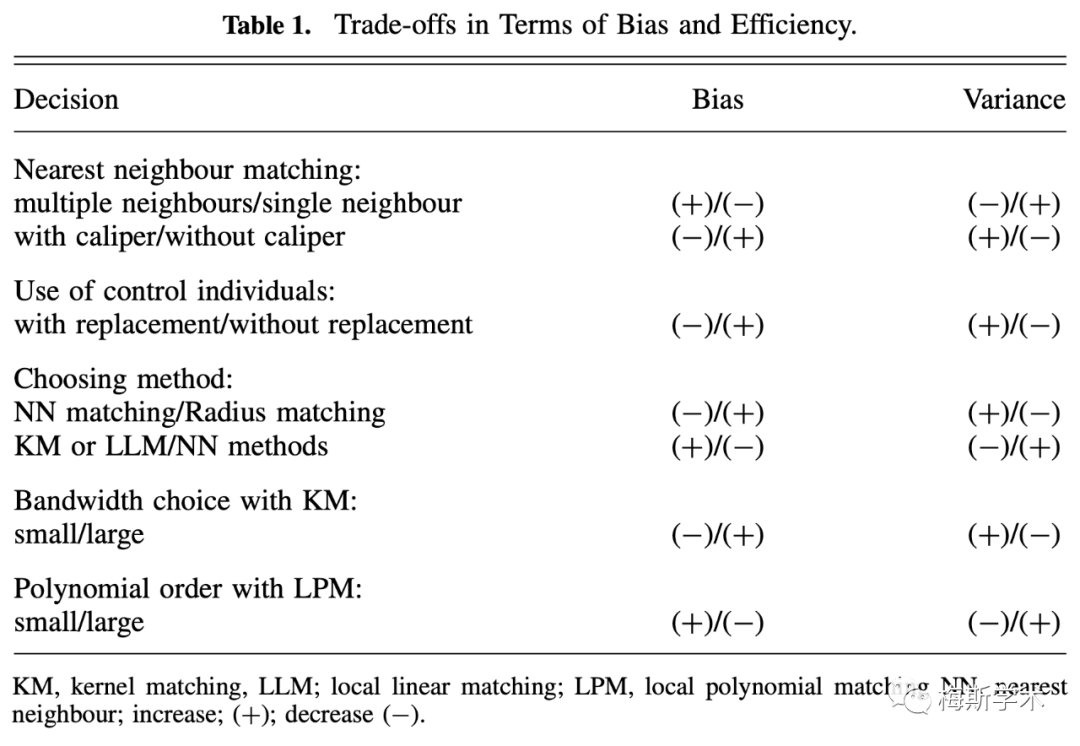
表1. 各匹配方法关于偏倚及有效性的比较(Caliendo, 2008)
Step 3. 重叠区域/共同支持域
两组倾向评分的重叠范围 (Overlap Region),又叫共同支持域 (Common Support Region),一般我们会剔除PS在重叠区域以外的离群值(outlier)。
重叠区域的大小是评估匹配效力的一个重要因素,如果重叠区域小或完全没有重叠,则表明两组完全没有可比性,无法进行匹配。
Step 4. 匹配效果评估方法
对于匹配效果的评估,比较直观的有观察PS在匹配前后的分布,以及特征在匹配前后的分布。如果要量化匹配效果,我们引入一个标准均值差(Standardized Mean Difference, SMD)的概念。
SMD = (实验组均值 - 对照组均值) / 实验组(或总体)标准差。一般当SMD<0.1时我们认为配平效果较好。
以上研究步骤均属于倾向性评分匹配 (PSM)。
② 逆概率加权 (IPW)
PS除了可以应用于匹配外,还有一种思路就是根据PS对每个个体赋予不同权重,从而构成一个虚拟的、标准化人群,使得研究组和对照组人群特征达到平衡。常用的一种方法就是逆概率加权(IPW)。
对于研究组,权重为1/PStreatment;对于对照组,权重为1/(1- PStreatment)。
与匹配相似,有时我们也会将赋予权重的对象限制在重合区域中。但因为不设置卡钳值,样本损耗会比匹配要小很多,可以应用于样本量不足以实现匹配的情况。
经过上述介绍,相信大家对混杂因素及其校正方式都有了一定了解。有关「如何在SAS和R中实现倾向性评分匹配和逆概率加权」,敬请期待后续两篇实操教程!
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言









