临床预测模型研究方法与步骤
2024-03-16 莫航沣, 陈亚萍, 韩慧,等。 中国循证医学杂志 发表于威斯康星
临床预测模型又称风险预测模型、预测指数、预测规则、风险评分,是一种通过纳入多个变量(如临床指标、生化指标、影像学等)预测结局发生情况的统计学模型[1-3],可对患者的疾病发生、严重程度分层、风险和转归
临床预测模型又称风险预测模型、预测指数、预测规则、风险评分,是一种通过纳入多个变量(如临床指标、生化指标、影像学等)预测结局发生情况的统计学模型[1-3],可对患者的疾病发生、严重程度分层、风险和转归等临床情况进行预测,帮助医生更准确地评估患者的疾病风险和预后,提高临床决策的准确性和个体化程度[4]。目前,大量预测模型在不同领域发表,同一个领域或同一个临床问题甚至存在多个模型,如:胰腺癌临床风险预测模型存在38种[5],COVID-19预后模型存在353种[6],2型糖尿病患者心力衰竭预后模型存在58种[7],难治性心肺衰竭患者体外膜氧合支持的死亡率预测模型58种[8],全膝关节置换术患者生活质量的预后模型存在12种[9],但这些模型很少在临床使用和推广。其中一个主要原因是这些预测模型研究的质量不高,模型在开发过程中存在各种问题,如结局指标不明确、缺少多方面性能评估、缺少外部验证等。例如,有研究者对涉及COVID-19的31个预测模型进行评价显示:大多研究过程中缺少完整研究设计和校准度的评估,所有模型都存在高偏倚风险[10]。因此,预测模型研究需要遵循规范的研究方法和流程。本文将详细介绍临床预测模型的基本类型、开发步骤和方法,旨在为研究者提供有关临床预测模型研究的方法指导。
1 临床预测模型研究及类型
1.1 临床预测模型分类
临床预测模型包括诊断模型和预后模型。诊断模型的预测目标是人群在当前时间点患有某种特定结果或疾病的概率,其重点关注当前状态[11]。预后模型估计个体在将来特定时间内(可以是今后几小时甚至几年)发生某种结局的概率[2,11]。预后模型不仅限于特定疾病患者的结局,也可以是非患病人群发生某种结果的风险预测[11]。诊断模型与预后模型的区别如表1。
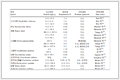 表1 诊断模型与预后模型的区别
表1 诊断模型与预后模型的区别1.2 临床预测模型研究分类
临床预测模型研究包括无外部验证的模型开发研究、有外部验证的模型开发研究、预测模型验证研究和预测模型临床效果研究四类,不同类型的预测模型研究证据强度不同,如表2所示,级别越高,证据可靠性越好[12-14]。
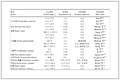 表2 临床预测模型研究分类及证据等级
表2 临床预测模型研究分类及证据等级2 临床预测模型开发研究基本步骤
临床预测模型开发的过程包括数据收集、模型构建、性能评估、模型验证、模型呈现和更新等环节(图1)。
 图1 临床预测模型开发基本步骤
图1 临床预测模型开发基本步骤2.1 数据收集
2.1.1 数据来源
恰当的数据来源可为模型开发提供丰富、有代表性的样本。诊断模型的数据来源主要为横断面研究和病例-对照研究,预后模型的数据来源则包括前瞻性队列研究、回顾性研究、疾病注册数据库和巢式病例-对照研究,详见表3[4]。此外,有学者提出某些情况下随机临床试验的数据可额外应用于预后模型的研究[15]。
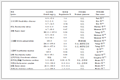 表3 常见预测模型研究数据来源
表3 常见预测模型研究数据来源2.1.2 潜在预测因子选择
研究者需通过查阅文献和资料,选择要纳入的潜在预测因子,即与结局可能相关的因素。预测因子主要包括:人口统计学特征(如年龄、性别、种族、教育、社会经济地位)、疾病类型和严重程度(如主要诊断、表现特征)、病史特征(如既往疾病发作、风险因素)、共病(伴随疾病)、病理学特征、医学影像、遗传特征、身体功能状态(如Karnofsky评分、世界卫生组织表现评分)以及主观健康状况和生活质量(心理、认知、心理社会功能)等[16]。对于预后模型,避免纳入与结局直接相关或直接确定的强相关预测因子,在患者明确已有其中一个阳性变量下,其已是预后结局明确的高危患者。相反,研究者应该关注与结局存在不确定性的预测因子,探究预测因子对结局事件的影响。
2.1.3 确定结局指标
对于诊断预测模型,其结局指标为疾病的存在与否。需要注意的是,预测因子测量和参考标准(金标准)之间的时间窗应尽可能短,在此期间不要开始任何干预。预后预测模型的结局指标相对于诊断模型更复杂,分为致死事件、非致死事件、以病人为中心和广泛负担的结局[17],见表4。生存结局是临床预测模型尤其是预后模型经常考虑的指标,研究者需要进行一定时间的随访,记录一段时间后结局的发生状况或多个时间节点的生存情况[18]。在选择结局指标时,需要综合考虑多个因素,确保选定的指标具有以下特点:良好的临床相关性,能够准确反映疾病的存在与否;较好的识别性,能够通过可靠的测量方法进行准确评估并且定义明确;良好的敏感性和特异性,能够正确识别真正发生的事件和排除未发生的事件;高可用性和可行性,易于在临床实践中获取和记录。此外,收集结局资料时是否采用盲法评估,尤其对主观性结局,会直接影响模型的预测情况以及造成偏倚。
 表4 结局指标分类
表4 结局指标分类2.1.4 样本量估计
足够的样本量可确保模型的性能,避免过度拟合等问题,但过多的样本量并不能提高模型的性能表现。EPV(events per variable)原则是估算样本量常用的方法,即临床预测模型中每个事件(发生的结局)对应的可用样本数量与预测变量的数量之比。如果结局事件发生率小于20%,EPV最好为20,至少为10,即每个变量至少有10个结局事件(样本量=变量数×10/发生率);如果事件发生率在20%~80%,EPV需更高[19]。样本量有时会受到未发生结局事件数量和预测因子效应及每一类预测因子事件数影响,这时使用EVP原则来确定样本量会受到质疑[20]。因此研究者也可根据样本量估算公式进行计算。例如:二分类结局预测模型研究所需样本量的计算公式为[21]:
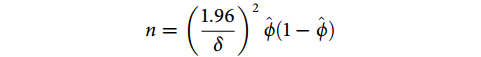 |
其中,需估计总结局事件的95%可信区间( )以及绝对误差范围(
)以及绝对误差范围( )。
)。
此外,在进行以时间为终点的生存事件结局的临床预测模型时需使用不同方法计算样本量,且两种类型的模型都可根据二分类结局模型的目标收缩因子和最小潜在过度拟合程度分别计算所需样本量,最后选择所需最小样本量[21]。
2.1.5 数据清洗
数据清洗主要包括:缺失值处理、编码预测因子、限制候选预测因子。缺失数据为常见的问题,分为完全随机缺失、随机缺失和非随机缺失[22],见表5。预测因子和结局的缺失在收集数据过程中都会发生且大多数无法避免,研究者可尝试使用替代值法、删除缺失值、最大似然估计、插补法及多重插补法等方法处理[22,23]。
 表5 数据缺失的类型
表5 数据缺失的类型分类变量在建模时编码为哑变量(虚拟变量);有序变量可视为无序变量,使用哑变量编码,或舍去小类别使用大类别。对于连续变量预测因子,可保留连续性变量或转换为等级资料,尽量避免转化为二分类变量,因为二分法会导致信息丢失,降低模型的效度[24]。最明显的影响可能是某些变量刚超过阈值或达到阈值,对个体没有太大的影响,但对结果产生影响。如刚达60岁的变量归入60岁以上,实际对目标结局影响有限。通过箱线图检查连续变量分布的离群值,即异常值和极值,研究者应先考虑是否发生输入错误以及检查其生物学合理性。在处理离群值时,推荐使用Winsorization(缩尾处理)代替移除法,该方法通过将离群值移到整体数据分布的中心,具有比简单的离群值移除法更好的性能[25]。限制候选预测因子除在研究设计时考虑入选的预测因子外,建模前研究者可通过减少有效的自由度来使模型更稳定。限制候选预测因子可采用预测因子的分布、合并相似变量、平均预测因子效益等方法。
2.2 模型构建
2.2.1 筛选预测变量
构建临床预测模型时,从潜在的预测因子中选择与结局事件密切相关的变量并纳入最终模型,这一过程称为选择主效应,又称筛选预测变量。筛选预测变量的方法包括全模型策略和筛选模型策略[26]。全模型策略不进行预测因子的筛选并要求将全部的潜在预测因子纳入模型,可避免过度拟合以及筛选偏倚,但存在易受到主观性影响、信息偏差、数据缺失和过度复杂性等问题[27]。因此推荐基于一定准则的筛选模型策略,常用的方法包括向后法(backward elimination,BE)、向前法(forward selection,FS)、逐步向前法、逐步后退法、增强后向剔除法、最佳子集选择、单变量分析和LASSO回归等,各方法的特点及优缺点详见表6[28]。单变量分析是一种常见的变量筛选方法,首先对每个变量进行单变量分析,并将满足显著性水平(通常是P<0.05)的变量纳入模型。但单变量分析忽略了变量之间的相互作用和潜在的共线性问题,不推荐使用。此外,在选择变量时,不仅依赖于显著性水平,还需要综合考虑可能存在的混杂因素和其他独立因素[29]。
 表6 常见变量筛选方法
表6 常见变量筛选方法2.2.2 模型拟合
使用筛选后的预测变量和其他需要考虑的变量,通过多因素模型来估计它们与感兴趣结局变量之间的关系,该过程为模型拟合,又称模型构建。不同的结局变量,适用的模型也不同,详见表7。Logistic回归、Cox回归等传统方法相对简单,易于解释结果,可以较为灵活的选择特征,得到每个预测因子对结果的影响,但存在变量相关性较强或交互作用时准确度可能下降,且由于是参数化模型,存在偏差或过度拟合问题。传统方法具有可解释性强和对小样本数据稳健的特点,但受限于线性关系的假设,难以处理复杂的非线性模式。机器学习和人工智能等现代方法在一定程度上弥补传统方法的局限,包括决策树、支持向量机、弹性网、LASSO回归、神经网络、贝叶斯网络、规则学习等。机器学习方法在处理非线性关系、提供高准确度以及自动特征提取方面表现出色,但可解释性较差,需要大量数据训练,并存在过拟合的风险[30]。
 表7 常见构建多因素模型方法
表7 常见构建多因素模型方法由于机器学习和人工智能缺乏可解释性和透明性,使用过程中难以解释其每个变量影响和决策过程,因此又称黑箱算法[31]。为了解释黑箱算法的过程以及不同特征对预测结果的影响以及提高其解释性。研究者可根据研究目的、研究性质、变量和变量属性等,选择合适的可视化解释工具展示每个变量对结局影响,如SHAP、LIME、ALE、DeepLIFT、DeepTaylor等[32]。
2.3 模型性能评估
临床预测模型的性能评估包括整体性能、区分度、校准、重分类和临床有用性5个方面[33]。开发预后模型时,可能面临多个时间节点下的生存情况,则需对模型的性能进行多次评估。
2.3.1 整体性能
模型整体性能是评估预测模型在数据集上的拟合程度或预测能力的指标,常用的评估指标包括R²和布里尔评分(Brier score)。R²衡量模型对目标变量变异性的解释程度,取值范围从0到1,越接近1表示模型解释能力越好。布里尔分数则用于衡量模型对观测结果与真实结果之间的差异程度,适用于二分类问题,取值范围从0到0.25,越接近0表示模型预测准确性越高。
2.3.2 区分度
区分度指模型在预测事件与非事件之间进行区分的能力。常用的区分能力指标包括C统计量(也称为Concordance统计量,C-statistic)和区分斜率。C统计量表示模型对于随机选择一对事件和非事件的患者,正确判断哪个风险更高的能力,C统计量在0.5~1之间,较高的值表示较好的区分能力,接近0.5表示区分度较低,越接近1表示模型越理想[34]。如果模型是二分类结局变量,受试者工作特征曲线下面积等于C统计量,可用于评估模型的区分能力。区分斜率用于描述预测模型中特定指标(例如连续变量)与预测结局之间的关系,在临床预测模型中能根据个体特征或子群之间的差异对斜率进行个性化解释和应用,提高模型的准确性和个体化的临床决策能力。
2.3.3 校准度
校准度或拟合优度指模型预测值与实际观察值之间的一致性[34]。常用的校准度指标包括大规模校准、校准斜率和Hosmer-Lemeshow统计量。大规模校准关注整体的校准情况,校准斜率则表示模型的预测风险与实际观察风险之间的比例关系,而Hosmer-Lemeshow统计量用于评估模型的整体校准程度。
2.3.4 重分类
重分类用于新旧预测模型比较并衡量模型的改进和增益,常见的重分类统计指标如净重新分类指数(net reclassification index,NRI)和综合判别改善指数(integrated discrimination improvement,IDI)[35]。NRI衡量了改进模型相对于基准模型在重新分类中的净改善情况,考虑了事件和非事件的正确分类以及错误分类的情况,可以评估改进模型的分类准确性。而IDI衡量了改进模型相对于基准模型在整体区分能力上的提升,通过计算改进模型和基准模型的预测概率之间的差异得到综合指标。
2.3.5 临床效益
临床效益与临床实践密切相关,它通过确定阈值、评估净收益和制定决策规则来评估预测模型的实用性和经济效益[36,37]。评估模型的临床效益可衡量模型在减少不良结果、提高治疗效果或优化资源利用方面的效益,通过分析决策曲线(decision curve analysis,DCA)评估预测模型在实际决策中的效果并确定最佳的决策阈值。在决策曲线中,存在两种极端情况:全部干预(治疗)和全部不干预(图2),只有模型的曲线在两者之上其临床效益才有应用价值,并且研究者可根据净收益情况确定最佳阈值概率。Kaplan-Meier分析是一种用于生存分析的统计方法,用于评估事件发生时间(如生存时间、治疗失败等)和患者生存率之间的关系。Kaplan-Meier分析不仅可以观察不同预测因子或变量对患者生存率的影响,也能展示预测模型的预测情况与实际情况的差别。
 图2 决策曲线
图2 决策曲线
横坐标为阈值概率,模型预测的概率超过阈值概率即为阳性或事件发生。在患者的预测概率达到阈值概率时,即采取相应的措施。但采取相应的措施不一定获得有利的结果,非阳性的病人可能也会被错误的定为阳性。此时,纵坐标为除去误诊(有弊)后的收益,即为净收益。黑色横线与红色斜线代表两种极端情况。黑色横线代表全部不干预,此时净收益为0,无治疗受益。红色斜线代表所有患者都进行了干预,但净收益随着阈值概率增加而减少。
2.4 模型验证
模型验证是评估预测模型性能和泛化能力的重要步骤,它包括内部验证和外部验证。内部验证通过在同一数据集上进行模型训练和评估来估计模型的性能,可以检查模型是否过度拟合或欠拟合。而外部验证则在独立的数据集上对模型进行评估,以验证模型的外推能力。
2.4.1 内部验证
内部验证指基于开发数据集进行模型评估得到模型的性能指标。内部验证方式从数据使用特征分为表观验证、随机拆分验证、交叉验证、Bootstrap方法和“内部-外部”交叉验证,如表8[4,38]。有研究表明随机拆分验证在大样本量时才有较好的表现,小样本量时不具有很好表现,但大样本量时表观验证优于随机拆分验证,因此随机拆分验证应该被更有效的技术取代,如加强法Bootstrap[38,39]。在大样本量、多中心的情况下,按时段分割数据、按中心分割数据或“内部-外部”交叉验证更具有效度[40]。无论是传统方法还是机器学习方法,在进行内部验证时所采用的方法在本质上并无明显差异。但机器学习在内部验证中使用区分度和校准度等传统性能指标外,还存在更复杂的指标,包含ABS、平衡精度(balanced accuracy,BAC)、AUC、F1得分和概率精度(probabilistic accuracy,PAC)[41];其数据集规模和多样性要求也更高。
 表8 内部验证方法
表8 内部验证方法2.4.2 外部验证
外部验证关注模型的可移植性和外推性,使用独立于开发样本的数据集来评估模型的性能,提供模型在其他数据集上性能的可靠估计,其数据来源需要专业知识以及流行病学研究的相关知识和专家来判断其有效性,才能够合理用于开发模型的外部验证[42]。根据“经验法则”,临床预测模型外部验证的样本量至少需要100个阳性事件或阴性事件,理想情况下需要200个(或更多)事件[43]。然而,一些研究指出这一规定可能存在一定的不确定性,并提出了一种基于Logistic的样本量方法,这种方法更加适合于外部验证预后模型[44]。如表9所示,根据数据来源将外部验证分为:时段验证、地理验证、领域验证、独立验证[4]。目前外部验证面临的主要问题是:缺少不同中心(相似)患者的共享数据库,分散地、单独地使用区域的患者数据验证模型的有效性是不准确的[1,40]。
 表9 临床预测模型外部验证方法
表9 临床预测模型外部验证方法2.5 模型呈现
临床预测模型的基本形式一般为数学统计模型,为增加模型的临床适用性和可操作性,往往需对模型进行可视化呈现。常见的呈现形式包括:回归公式、简化表格评分系统、图形分数评分、列线图、移动网站和程序[45]。简化表格评分系统和图形分数评分临床上相对简单易理解,但可能会存在误差。列线图是一种直观易懂的可视化工具,能够整合多个预测因素并帮助进行个体风险评估和决策制定,但依赖于特定模型并可能存在信息简化和解读误差的限制。移动网站和程序可以通过输入特定临床信息得出结局的发生概率,方便快捷且利于个性化,但对设备可能有要求。最佳的呈现形式应该基于环境和使用人群,研究者应根据实际情况选择合适的呈现形式。
2.6 模型更新
理想的预测模型能在不同的时间和地点为患者提供准确的预测结果。当使用的环境和开发模型的样本类似或无新相关指标出现时,可以通过观察结果和模型预测比较来评估模型的效度。更新模型时,研究者可以仅更新风险基线,也可以对模型进行重校准、重评估、扩展、修订、系数收缩,需要注意的是风险生存模型需要更新预后指数以及按照时间点重新校准[4]。更新模型的主要方法可以归结为回归系数更新、Meta-model法及动态模型构建三类[46]。
3 预测模型研究报告规范
预测模型研究报告遵循个体预后与诊断模型研究报告规范(transparent reporting of a multivariable prediction model for individual prognosis or diagnosis,TRIPOD),适用于模型开发、验证和更新研究,也用于评估研究报告时作为参考。TRIPOD包含22个项目清单,涵盖了预测模型研究的报告要求,如研究目的、数据收集、模型开发和验证、结果解释和模型应用等[11,13,47],旨在提高预测模型研究的透明度和报告质量。机器学习预测模型在遵循传统的TRIPOD声明时,面临一些特殊挑战和不足之处。首先,机器学习模型通常被认为是黑箱模型,其内部决策过程和特征的影响难以解释,与TRIPOD声明中要求的模型透明度存在矛盾。其次,涉及最关键输入变量的特征选择和改进及转换原始数据的特征工程为机器学习的重要步骤,但TRIPOD声明未提供详细的报告指导,导致无法为机器学习建模过程提供帮助[41]。最后,机器学习模型的验证策略通常更复杂,其性能评估指标包含传统指标和专用指标,可能导致在报告和理解方面存在困难,需更具体的指导。
4 临床预测模型研究质量评价
与其他研究一样,开发临床预测模型也会产生偏倚风险,PROBAST(prediction model risk of bias assessment tool)工具用于评估预测模型开发研究偏倚风险及其适用性,为模型的选择、改进和应用提供支持。PROBAST工具包括研究对象、预测变量、结局和统计分析4个领域共20个条目,涵盖了预测模型开发和验证过程中的关键偏倚风险来源,如样本选择、数据收集、模型选择和评估等[48,49]。研究者进行模型开发研究时可作为参考,提高模型研究的质量。此外,PROBAST工具基于传统建模方法开发,用于评价机器学习模型时仍存在一些不足。其主要区别体现在机器学习模型开发、验证、性能评估方面存在不同方法和额外指标,仅使用PROBAST工具对模型的质量和偏倚风险评估可能不适用[50,51]。
5 总结
预测模型研究质量关系到预测模型能否指导临床决策,研究者需确保采用合适且准确的步骤。预测模型开发过程包括明确研究设计、数据收集、模型开发、性能评估、模型验证、模型呈现和更新。预测模型的研究报告遵循TRIPOD声明,偏倚风险和适用性评价采用PROBAST工具。随着数字化和智能化医疗时代的发展,机器学习和人工智能模型已经拓展到临床决策和护理等领域,不再局限于影像学和生物信息学。因此,机器学习和人工智能模型也带来了新的挑战,涉及模型的复杂性、解释性、特征处理、模型评估以及性能指标的详细报告。由于机器学习和人工智能模型的特殊性,现有的评估框架和标准可能不再适用,因此需要制定新的评估框架或标准,以应对这些新挑战。机器学习和人工智能预测的相关评估工具PROBAST-AI和TRIPOD-AI规范正在研究和开发中,以帮助研究者更好地报告和评估模型的质量[52]。新的规范将有助于确保临床预测模型在临床实践中的可靠性和可用性,促进数字医疗领域的发展。
原始出处:
莫航沣, 陈亚萍, 韩慧, 章亚平, 刘雨今, 张妹, 鲁小丹, 华雨婷, 诸宇佳, 蔡婷婷, 夏云辉, 沈建通. 临床预测模型研究方法与步骤. 中国循证医学杂志, 2024, 24(2): 228-236. doi: 10.7507/1672-2531.202308135
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言






#临床预测模型#
37