随机试验中分配序列的生成与隐藏
2015-01-18 MedSci MedSci原创

随机对照试验提供了临床研究的金标准。随机化首先取决于两个内在相关但彼此独立的步骤,即产生一个不可预测的随机分配序列及隐藏此序列直至分配开始,即为分配隐藏(allocation concealment)。但是,随机化也许是试验中最不容易被理解的部分。任何不恰当的随机化皆导致选择偏倚和混杂偏倚。研究者应摒弃所有非随机的系统性分配方法。受试者的分配入组应为一随机化的过程。 简单(非限制性)随
随机对照试验提供了临床研究的金标准。随机化首先取决于两个内在相关但彼此独立的步骤,即产生一个不可预测的随机分配序列及隐藏此序列直至分配开始,即为分配隐藏(allocation concealment)。但是,随机化也许是试验中最不容易被理解的部分。任何不恰当的随机化皆导致选择偏倚和混杂偏倚。研究者应摒弃所有非随机的系统性分配方法。受试者的分配入组应为一随机化的过程。
简单(非限制性)随机化法是最基本的序列生成过程。抛硬币(coin-tossing)、掷骰子(dice-throwing) 以及分发事先洗好的牌是合理的生成简单完全随机序列的方法。但小样本中的简单随机化可以形成各组之间完全不相同的样本大小,难于执行并且无法验证,建议研究者避免使用。用随机数字表(random numbers table) 或者电脑随机数产生器分配受试者的序列更加可靠,因为它们是可以验证的不可预测的、可靠的、简单的、可重复的方法。

限制性随机化方法(restricted randomisation) 控制了出现非期望的样本不平衡的概率。换句话说,如果研究者希望各治疗组的样本大小相等,应该使用限制随机化。
最常用的达成平衡随机化(balanced randamisation) 的方法是区组(blocking)随机化。例如,一个区组大小为6 ,依次纳入的每6个受试者为一组,通常3 个被分配到一个治疗组,另外3 个被分配到另一组。但是,分配比率可以是不平均的。例如,每个按照2: 1比例分配的大小为6 的区组中,其中4 个人被分配到一个治疗组,2 个被分配到另一治疗组。这种方法可以很容易扩展到两个以上的治疗方案。如果应用这一方法,研究者应该随机改变区组的大小并使用较大的区组大小,特别是在非盲法试验中。
随机分配规则(random allocation rule) 是限制的最简单形式。研究者定义一个整体样本大小然后随机选择样本中的一个子集分配到A 组,剩下的分配到B 组。例如,总样本量大小为200,在一个帽子里放100只A 组的球和100只B 组的球,将它们随机拿出来并且不再放回帽子里,这就是随机分配规则的符号化。生成序列时会随机指定100 个A 组和B 组的分配顺序,这个方法将整个研究总体当作一个大的区组,即此平衡通常只在试验结束时达成,而非贯彻整个试验过程。
替换随机化法(replacement randomisation) 重复简单随机分配方案直到达成某一预期的平衡。,它易于实施,能确保合理化的平衡,并包括了不可预测性。其主要的缺陷是不能确保期中分析所需要的试验全程的平衡性。
偏性掷币设计(biased-coin design)在试验过程中改变分配概率以纠正可能发生的不平衡性,可以达到与区组法相同的目的而无需强制严格平均。
"瓮随机化法"(umrandomisation),将简单随机和限制性随机法的好处结合起来,当达到某一平衡时最大限度地保护了不可预测性。分层随机化法(stratified randomisation)对重要的预后因素进行预随机化分层以避免不平衡性,如年龄或疾病的严重程度。

产生一个恰当的随机序列表花费的时间和精力很小,但可获得很大的科学精确性和可靠性。研究者应致力于用恰当的资源来生成恰当的随机试验并清楚地报告他们所用的方法。
序列分配隐藏
研究者应确保在随机设计中一个不可预测的随机分配序列生成和充分的分配隐藏(allocation concealment)。 这两方面的任意一个错误都将损害随机化,导致不正确的结果。分配隐藏程序使得临床医师和受试者不知道下一例的分组情况。没有它,即使已经生成了恰当的随机 分配序列也可以被推翻。按照现有的关于预后因素的观点,有的患者可能会被分配到被认为不适合的治疗组,如果事先知道下一个分组方案,有的研究者会因此而排 除这个患者人组。同样地,预知下一个分组也可以将某些受试者分配至所认为的合适的组。不充分的分配隐藏致使试验中出现偏倚。事实上,缺乏充分的分配隐藏的 话,不管有没有一个随机(不可预测)序列都没什么不同了。通过从已发表的报告中评估分配隐藏,读者会很容易明白如何合理达成这些标准。

作 为随机化的一个直接结果,许多随机对照试验的报告中的第一个表格描述了各个比较组之间的基线特征。研究者应该报告关于重要预后变量的基线比较。读者应该在 考虑所测得的变量预后强度和已经产生的机遇不平衡的程度的基础上观察各组的可比性,而不要根据基线的统计学显著性检验考虑组间的可比性。对于连续变量,如 年龄、体重,研究者应用一个均值和一种检测变异度的方法,通常是平均值和标准差来描述。如果数据分布不对称,用中位值和百分位数范围(即四分位数间距)来描述更好。变异度不应该用标准误和可信区间来表述,因为它们是推论而不是描述性统计。数目和比例用于报告分类变量。
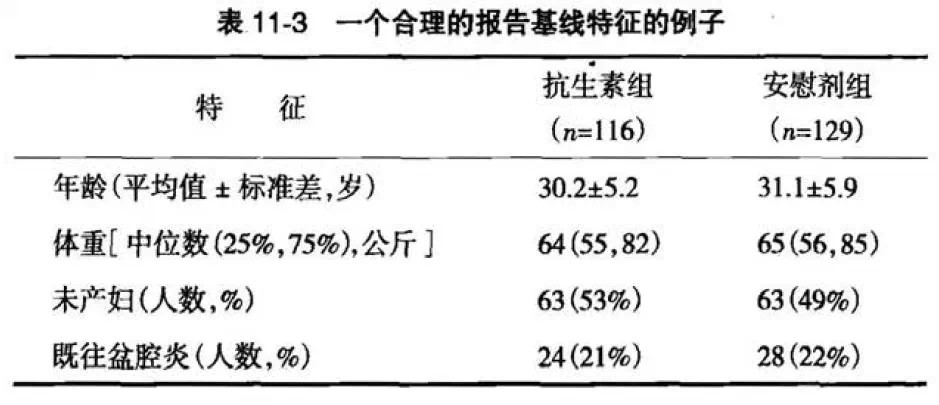
分 配隐藏与实施分配序列的技术有关,而与生成分配序列的技术无关。恰当执行分配隐藏给研究实施者增添麻烦,这会让临床医师感到不高兴。许多参与试验的人会试 图破译分组的序列,这一行为违反了随机化。对于一些实施试验者而言,破译分配序列经常成为一项无法抗拒的智力挑战。无论他们的动机是单纯的或恶意的,这种 意图都损害了试验的有效性。事实上,不充分的分配隐藏通常会导致高于预计的治疗效果,但偏倚在两个方向上均可出现。试验研究者会竭尽所能地努力破译分配序 列,因而试验设计者必须在设计试验时也努力地防止破译发生。研究者们必须恰当运用分配隐藏以有效地避免选择偏倚和混杂偏倚。此外,研究者应报告有关重要预 后变量的基线比较。然而基线特征的假设检验是多余的,如果其导致研究者回避报告任何的基线不平衡则可能是有害的。

医学研究会认为关于使用链霉素治疗肺结核的对照试验是里程碑的原因,并不像通常所认为的那样只是由于应用了产生分配顺序的随机数字表,更是因为其清晰地讲述了用来向所有参与入选病人的人员隐藏分组顺序的防范方案。
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言





#随机试验#
102